
Large Language Models for Feedback Analysis: Which ones are cutting-edge?
Explore Thematic’s expert approach to evaluating top LLMs for feedback analysis, using advanced NLP to turn raw data into actionable insights. Learn how we commercialize cutting-edge AI to streamline and enhance customer feedback evaluation
There is a lot of talk about Generative AI and Large Language Models. Analysts and vendors encourage everyone to jump on the “AI train” to save costs and upskill yourself. Practitioners share war stories of working with data scientists to test out the latest LLMs.
When it comes to Gen AI, there’s lots of marketing speak, but then, there’s research! At Thematic, we’ve spent close to 10 years applying AI models to feedback analysis. Here’s what we learned and how we approach this problem.
Let’s start with the basics…

What’s the difference between different AI models?
An AI model is any system that mimics human intelligence. Think of it as the parent category for all other models explained below:
What’s an ML model?
A Machine Learning (ML) model is a specific type of AI model that learns from data to make predictions or decisions without being explicitly programmed for those tasks. Typically, a ML model is trained for a specific task on data with labels to then make predictions on data without labels.
For example, an ML model in the feedback analytics / Voice of Customer space could predict Net Promoter Score (NPS) from various signals such as behavioral and operational data, combined with customer feedback.
What’s a language model?
A language model is a type of AI model focused specifically on understanding and generating human language (a specialized child of AI models). These models can be supervised and unsupervised.
Supervised language models are similar to other ML models. They tend to be trained on language data only. The labels it can predict range from binary (e.g. spam / not spam), numeric (e.g. a sentiment score from -1 for negative to +1 for positive), to categorical.
In feedback analytics, you could train a supervised categorization model based on possible themes in feedback, e.g. “broadband speed”, “engineer visit”, or “contract renewal”. But you need to know these labels in advance. The model will struggle in cases where there are too many categories overall, more than one category per piece of feedback, or when the categories are too similar.
Unsupervised language models could return the most similar words given an input word. It could also predict the next word in a sentence (e.g. as you type a message in your phone).
What’s a large language model or an LLM?
An LLM is a large and advanced version of language models capable of performing a wide range of tasks with high proficiency (the powerhouse child of language models).
Unlike other AI models, they tend to be general purpose. ChatGPT is a great example of an LLM, but there are many others too. In the example of feedback analysis, they can do the same thing as traditional language models, such as categorizing text, but they can also summarize text or interpret and answer natural language questions.
General-purpose LLM’s trump custom models: Here’s why
There is a lot of talk about pre-trained models, custom models or domain-specific models. For example, trained on call center data only, or surveys. Vendors are quick to advertise these, or they even share that the models have been refined over a decade! Don’t buy into the marketing speak. Here’s how to think about custom models.
When it comes to ML models, like one predicting NPS from various signals, custom models are often best. They are fast and deliver high accuracy with even a small amount of clean training data. Data quality here is more important than data volume.
But when it comes to Generative AI, here’s a surprising fact: A custom model often performs worse than a generic model! Why is that?
Let’s first look at what it actually means to create a custom LLM…
There are two kinds of custom LLMs:
1. an LLM trained from scratch and
2. a generic LLM fine-tuned on a specific use case.
Sometimes, people refer to Retrieval-Augmented Generation (RAG) systems as custom LLMs, but that’s technically not correct. More on this below.
Training an LLM from Scratch
It costs many millions of dollars to train an LLM from scratch. You also need access to a lot of data that can be used to train the AI. Companies don’t usually let vendors use their data for training, rightfully so.
Fine-tuning a generic LLM
Fine-tuning an existing model is cheaper than training from scratch. Depending on the task, it can result in better performance. But of course it still takes time and resources to do it. Often, by the time you ship a fine-tuned model, a new better-performing generic LLM is released. For us, so far it hasn’t been worth it.
Case study: Bloomberg’s custom LLM
General purpose LLMs are often trained on much larger volumes of public data. And sure, some of it might not be relevant to your business, but the most important purpose of an LLM is language understanding. We’ve seen how quickly more accurate and cheaper LLMs are released by the big players.
For example, in 2023, Bloomberg spent $10M to train a custom LLM on their own financial data, called BloombergGPT. When GPT-4 was released, JP Morgan AI research team tested it alongside BloombergGPT and found that GPT4 outperforms it on financial text tasks.
So, while a domain-specific LLM can be great for marketing, it doesn't necessarily mean better accuracy or insights.If a vendor tells you it is, ask them which model they have compared it to. It’s probably an older LLM.
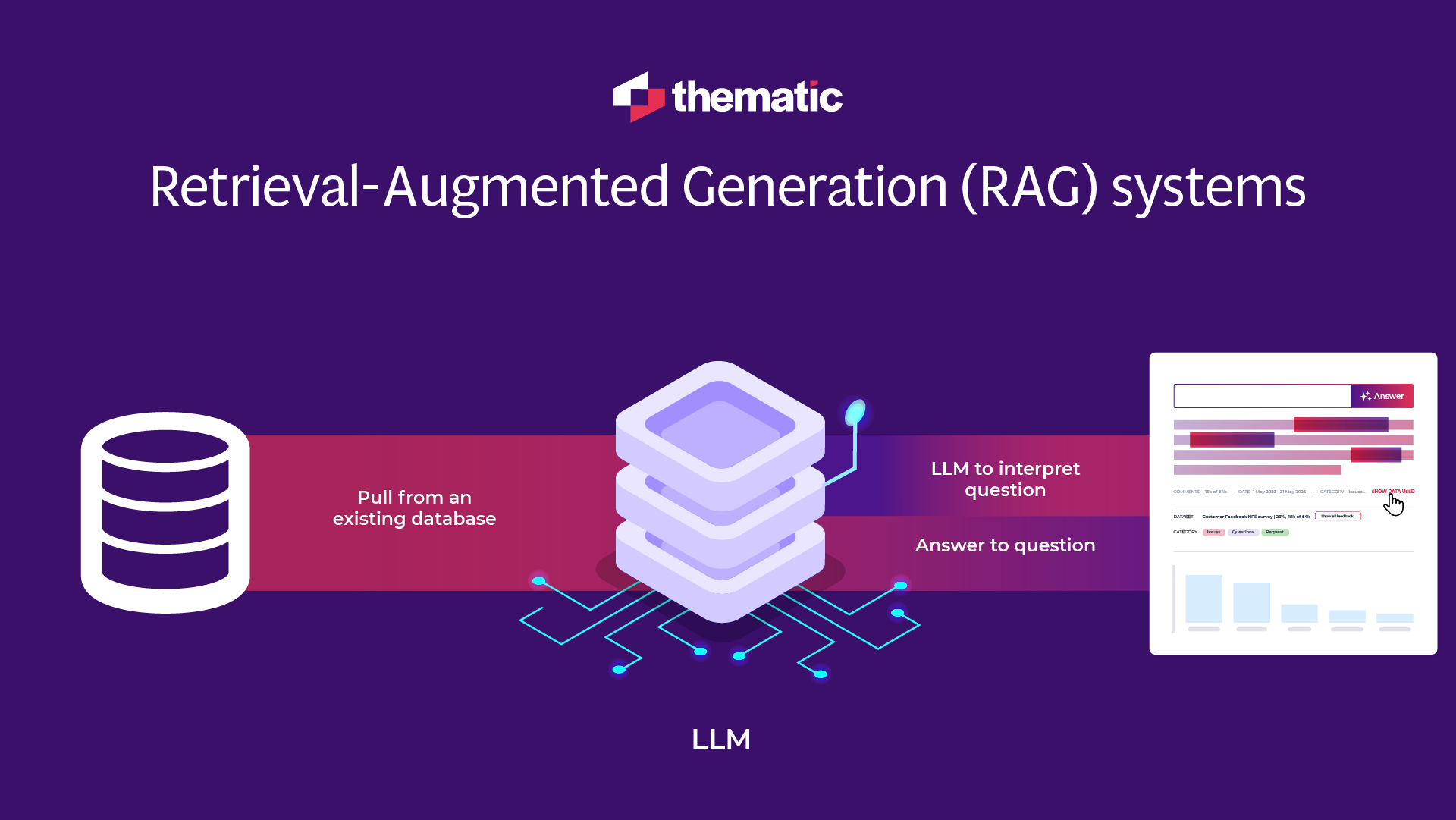
What about RAG systems as “custom LLMs”
Often vendors refer to RAG systems as “custom LLMs”. In reality, they still use general-purpose LLMs. They first pull from a database the data required to answer a question, and then ask LLM to interpret that question. This is a valid approach to circumvent the token limit requirement and reduce hallucinations. We use a variation of this at Thematic.
In general, rather than customizing LLMs, the focus should be on improving the prompts or inputs to the LLM to generate a higher quality result. When you give better quality of context to the model, it will produce better quality results.
That said, better models are released all the time, so it’s also important to keep testing newer models. With each release, they deliver increasingly accurate output that is faster and more affordable. Just this week, Claude 3.5 Sonnet was released, outdating GPT4o and Claude 3 Opus on key evaluations and speed.
How to make sure your AI-powered feedback analytics is always cutting-edge
At Thematic, we focus on staying agile and up-to-date with the latest models. Rather than invest heavily in a single model, we create a process to evaluate, optimize, and select from various models based on factors like accuracy, latency, and security. This approach ensures we are not tied to an outdated model and can continuously improve and adapt to the latest advancements.
When it comes to evaluating Large Language Models, we have built a process that concurrently evaluates all major 3rd party and hosted LLMs. We always use carefully selected data and manually verified answers. We find that LLMs vary in not just accuracy but also speed on different tasks.
Prompt engineering or fine-tuning
Technically, prompting and fine-tuning are two sides of the same coin, and we found that prompting gives our customers better and more sustainable accuracy advantages. We're not disregarding the fine-tuning approach but, for now, we haven't seen the quality of results and cost-effectiveness to make it worth the investment.
So, in addition to evaluating and swapping models for best-performing ones, we also meticulously craft our prompts. Each prompt is optimized to deliver high accuracy. We use Automatic Prompt Engineering to find the best ones for each task.
The result? Our Generative AI always stays current with the time!
For example, we recently released a new AI-powered feature: linking parts of a conversation summary to the original place in the transcript. Since then, new models have been released and we were able to immediately test them. One of them outperformed the older models, so we immediately put it into production.
So while other providers might say in their marketing, that their language models have been fine-tuned over many years or even decades, at Thematic we always use the latest and most current models.
That said, the best model and the best prompt is just part of the answer…
Which model is the best for Voice of Customer / Feedback analytics?
In the space of feedback analytics, the complete solution is more important than which individual model you use. In Thematic, we combine traditional language models and carefully selected and optimized LLMs. Depending on the task, we chose the best one depending on the speed and accuracy.
Apart from the model itself, the ability to incorporate human feedback is critical to get the best possible outcome for our users.
With some AI-driven solutions, you will be able to edit extensively and take complete ownership of the taxonomy (this is where Thematic sits). Others however are less permissive and will require you to put in a ticket to the provider for them to advise and make changes on your behalf. This approach requires ongoing maintenance and is more time-consuming.
How to assess AI models
We always follow a robust process of evaluating AI models. Interestingly, there has been specific research into criteria for assessing AI, proposed by Cassie Kozyrkov, former Google Chief Decision Scientist:
- Ask what the AI is designed to do?
For us at Thematic, the objective is clear: to transform large volumes of unstructured data, such as survey open-ends, product reviews and support conversations, into a clear understanding of issues, so organizations make better decisions and drive business growth.
Key results are accuracy, latency and security, as these are key for helping companies turn data into insights they can rely on.
- Check the quality of data fed into the model, and whether it's right for the objective
Thematic ingests Voice of Customer and Voice of Employee data gathered through surveys, conversations, app reviews and experience management tools. Our pre-processing makes sure that there are no duplicates, all sensitive information is redacted and the data is complete and current. There is also an interface in the platform where users can validate the quality of the source data, building trust and confidence that the insights are generated on relevant data.
- Test that AI delivers what's needed, comparing accuracy, depth, speed
Users can also easily review if the AI delivers results that make sense, given the data it's analyzed. For example, for a piece of feedback on a webcam, "Get's the job done, but it's not cheap!", you can check the original comment to see if both the positive and the negative sentiment are highlighted, along with themes of Product Functions, Price, and Value for money.
Throughout Thematic's platform, you can see how the AI has analyzed a phrase. The themes and the sentiment are highlighted in the original voice of customer data, and its metadata can be verified in one click. "It's like looking under the hood to check everything is working," said Mick Stapleton, Head Analyst of Feedback at Atlassian.
In addition, users can easily check if the AI delivers similar results to manual or pre-existing analysis, with a subset of their data. For example, you can run 200 rows of data through Thematic and see how it compares to their existing analysis.
So, whether you’re deciding on a custom taxonomy or a Generative AI model, the key message here is checking what the AI is designed to do, checking the quality of inputs you give the AI and testing that it delivers what you need. The better the inputs, the more reliable your results become. And when it comes to Generative AI, a general model is best.
Staying at the forefront of AI skills, consistency and investment
We often hear that LLMs solve feedback analysis for companies, but it’s just one of the components of a full solution. And these components are improving at a rapid speed. Staying on top of this is not trivial.
Your team doesn't need to be reading papers every day, struggling to keep up with the industry's breakneck pace. Let us do the work, and we'll keep you updated and informed of how best to take advantage of these exciting developments.
Conclusion: Diving into AI & LLMs?
If you're diving into AI, especially with Large Language Models (LLMs), you should really think about going with a general-purpose model instead of a custom one. Why? Because AI is moving at lightning speed, and keeping up means you need the flexibility of something more universal.
We use the latest models and have an agile evaluation process. We're always checking on key areas like accuracy, speed, and security to keep everything top-notch. One big focus for us is prompt engineering, which basically means fine-tuning how questions are asked to get the best answers. This method tends to be more effective and long-lasting compared to endlessly tweaking the models themselves.
If you look at some real-world examples, like Bloomberg's custom LLM versus GPT-4, the general-purpose models usually win. Thematic's tactic of sticking with these adaptable, ever-improving models means we can hit high performance without investing heavily into a custom model that is quickly made redundant.

Our approach at Thematic remains flexible and agile, allowing us to evaluate new models as they become available and switch to them when necessary.
We promise to our customers that what we offer today, next month, and next year always draws on the best AI approach for analyzing unstructured data at scale.
Want to learn more?
The best way to experience Thematic's AI approach is to try it on your unstructured feedback data. Thematic offers a free trial for companies with high volumes of comments so that you can see how easy it is to get quality insights at scale.
Book a demo with Thematic to see how it works on your data.

Stay up to date with the latest
Join the newsletter to receive the latest updates in your inbox.


