Manual Rules for Text Analytics: Why They Often Miss the Mark (Part 2/5)
Manual rules are a popular text analytics approach, but they have significant flaws. Discover why they struggle with multiple meanings, sentiment, and evolving language.
Today, I’ll turn to the second approach. Also quite popular. It’s based on Manual Rules, and is closely related to word spotting. Both approaches operate on the same principle of creating a match pattern, but these patterns can also get quite complex.
For example, a manual rule could involve the use of regular expressions – something you can’t easily implement in Excel. Here is a rule for assigning the category “Staff Knowledge” from a popular enterprise solution Medallia:
Majority of Text Analytics providers as well as many other smaller players, who sell Text Analytics as an add-on to their main offering, provide an interface that makes it easy to create and manage such rules. They also sometimes offer professional services to help with the creation of these rules.
The best thing about Manual Rules is that they can be understood by a person. They are explainable, and therefore can be tweaked and adjusted when needed.
But the bottom line is that creating these rules takes a lot of effort. You also need to ensure that they are accurate and maintain them over time.
To get you started, some companies come with pre-packaged rules, already organized into a taxonomy. For example, they would have a category “Price”, with hundreds of words and phrases already pre-set, and underneath they might have sub-categories such as “Cheap” and “Expensive”.
They may also have specific categories setup for certain industries, e.g. banks. And if you are a bank, you just need to add your product names into this taxonomy, and you’re good to go.
The benefit of this approach is that once set up, you can run millions of feedback pieces and get a good overview of the core categories mentioned in the text.
But, there are plenty of disadvantages for this approach, and in fact any manual rules and word spotting technique:
1. Multiple word meanings make it hard to create rules
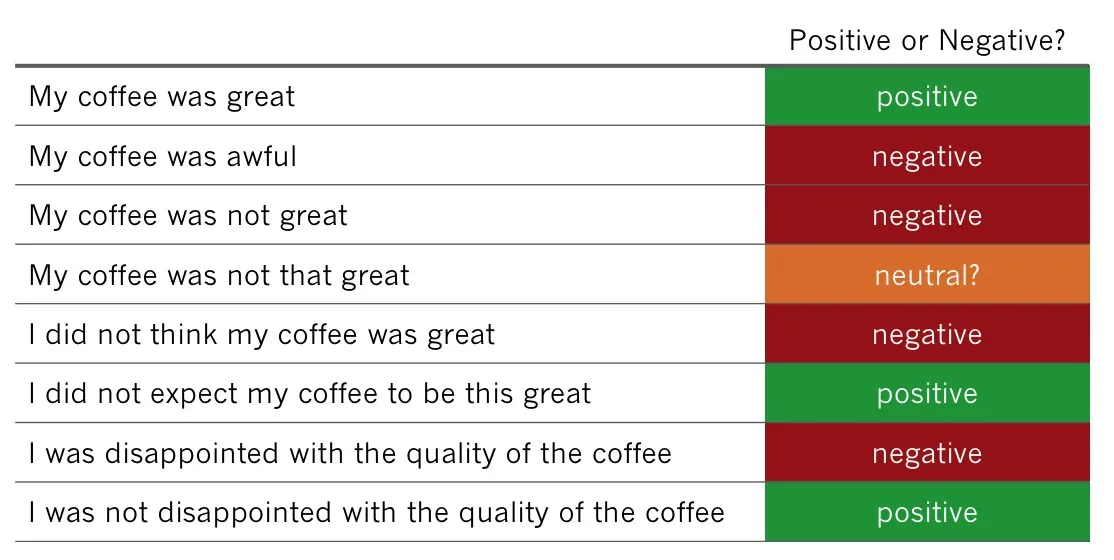
The most common reason why rules fail stems from *polysemy*, when the same word can have different meanings:
2. Mentioned word != core topic
Just because a word or a phrase is mentioned in text, it doesn’t always mean that the text is about that topic. For example, when a customer is explaining the situation that leads to an issue: “My credit card got declined and the cashier was super helpful, waiting patiently while I searched for cash in my bag.” This comment is not about credit cards or cash, it’s about the behavior of the staff.
3. Rules cannot capture sentiment
Knowing the general category alone isn’t enough. How do people think about “Price”, are they happy or not? Capturing sentiment with manually pre-set rules is impossible. People often do not realize how diverse and varied our language is.
So, a sub-category like “expensive” is actually extremely difficult to model. A person could say something like “I did not think this product was expensive”. To categorize this comment into a category like “good price”, you would need a complex algorithm to detect negation and its scope. A simple regular expression won’t cut it.
Thematic
AI-powered software to transform qualitative data at scale through a thematic and content analysis.
4. Taxonomies don’t exist for software products and many other businesses
The pre-set taxonomies with rules won’t exist for non-standard products or services. This is particularly problematic for the software industry, where each product is unique and the customer feedback talks about very specific issues
5. Not everyone can maintain rules
In any industry, even if you have a working rule-based taxonomy, someone with good linguistic knowledge would need to constantly maintain the rules to make sure all of the feedback is categorized accurately. This person would need to constantly scan for new expressions that people create so easily on the fly, and for any emerging themes that weren’t considered previously. It’s a never-ending process which is highly expensive.
And yet, despite these disadvantages, thisapproach is the most widely used commercial application of Text Analytics, with its roots in the 90s, and no clear path for fixing these issues.
So, are Manual Rules good enough?
My answer to this is *No*. Most people who use Manual Rules are dissatisfied with the time required to set up a solution, with the costs to maintain it, and how actionable are the insights.
Request a demo of Thematic's Customer Intelligence Platform
Thematic turns fragmented feedback into one consistent source of customer truth — so every team acts on the same customer story. Up and running in days, not quarters.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.