Six text analytics approaches exist with different accuracy and setup requirements: word spotting, manual rules, text categorization, topic modeling, LLMs, and thematic analysis.
Rule-based methods (word spotting, manual rules) require months of setup and miss emerging themes; accuracy often below 50%.
Machine learning approaches (text categorization, topic modeling) need extensive training data and struggle with transparency and new patterns.
LLMs offer powerful insights but face challenges with cost, hallucinations, and lack of transparency, requiring human oversight for enterprise use.
Thematic analysis extracts themes bottom-up using AI without training data, combining LLM power with human-in-the-loop validation for transparent, research-grade insights.
Businesses generate massive amounts of text data: customer feedback, online reviews, survey responses, and social media comments.
But without the right tools, making sense of all this information can be overwhelming. This is where text analytics comes in.
Text analytics is the process of extracting insights from unstructured text. By analyzing patterns, themes, and sentiments, businesses can uncover valuable trends and customer opinions that help you make better decisions.
With various text analytics approaches available, choosing the right one can be complex.
This guide breaks down six key text analytics methods, explaining how they work and when to use them.
Let's dive in!
Some Text Analytics background…
For a long time, I've been planning to write a post to clarify what's possible in text analytics today.
Throughout my career, I've spoken with many who are living through the pain of analyzing text and trying to find a solution.
Some try to reinvent the wheel by writing their own algorithms from scratch. Others believe that Google and IBM APIs are the saviours. Others again are stuck with technologies from the late 90's that vendors pitch as "advanced Text Analytics."
I've spent the last 15 years in Natural Language Processing, specifically in the area of making sense of text using algorithms: researching, creating, applying, and selling the technology behind it.
My academic research resulted in algorithms used by hundreds of organizations (I'm the author of KEA and Maui, which Thematic no longer uses as we've pivoted to LLMs). The highlight of my text analytics career was at Google, where I wrote an algorithm that can analyze text in languages I don't speak.
And for the past years, in my role as the CEO of Thematic I've learned a lot about what's available in the market.
So, it's fair to say, I'm qualified to speak on this topic.
I'll try to be objective in my review, but of course, I'm biased because of my position. Happy to discuss this with anyone who is interested in providing feedback.
Text analytics approach 1: word spotting
Word spotting matches keywords to categories but achieves only 50% accuracy at best.
First off, it's not a thing!
The academic Natural Language Processing community does not register such an approach, and rightly so. In fact, in the academic world, word spotting refers to handwriting recognition (spotting which word a person, a doctor perhaps, has written).
However, when it comes to how text analytics works, to my knowledge, word spotting is not used for any type of text analysis.
But I've heard frequently enough about it in meetings to include in this review. It's loved by DIY analysts and Excel wizards and is a popular approach among many customer insights professionals.
The main idea behind word spotting is this: If a word appears in text, we can assume that this piece of text is "about" that particular word.
For example, if words like "price" or "cost" are mentioned in a review, this means that this review is about "Price."
💡
The beauty of the word spotting approach is its simplicity.
You can implement word spotting in an Excel spreadsheet in less than 10 minutes. Or, you could write a script in Python or R. Here's how.
How to build a text analytics solution in 10 minutes
You can type in a formula, like this one, in Excel to categorize comments into "Billing", "Pricing" and "Ease of use":
And voilà!
Here it is applied to a Net Promoter Score survey where column B contains open-ended answers to questions "Why did you give us this score":
It probably took me less than 10 minutes to create this, and the result is so encouraging!
But wait…
Everyone loves simplicity, but in this case, simplicity sucks
Various issues can easily crop up with this approach.
Here, I've annotated them for you.
Out of 7 comments, here only 3 were categorized correctly.
"Billing" is actually about "Price", and three other comments missed additional themes. Would you bet your customer insights on something that's at best 50% accurate?
When word spotting is OK
You can imagine that the formula above can be tweaked further. And indeed, I've talked to companies who hand-crafted massive custom spreadsheets and are very happy with the results.
If you have a dataset with a couple of hundred responses that you only need to analyze once or twice, you can use this approach.
If the dataset is small, you can review the results and ensure high accuracy very quickly.
When word spotting fails
As for the downside? Please don't use word spotting:
If you have any substantial amount of data, more than several hundred responses
If you won't have time to review and correct the accuracy of each piece of text
If you need to visualize the results (Excel will hear you swearing)
If you need to share the results with your colleagues
If you need to maintain the data consistently over time
There are also many other disadvantages to DIY word spotting, that we'll discuss in the next section. I'll also talk about what actually does work and is a good approach.
Manual rules use pattern matching to categorize text but require months of setup and ongoing maintenance.
The Manual Rules approach is closely related to word spotting. Both approaches operate on the same principle of creating a match pattern, but these patterns can also get quite complex.
For example, a manual rule could involve the use of regular expressions (pattern-matching formulas that find specific text structures). Something you can't easily implement in Excel.
Here is a rule for assigning the category "Staff Knowledge" from a popular enterprise solution Medallia:
Majority of Text Analytics providers as well as many other smaller players, who sell Text Analytics as an add-on to their main offering, provide an interface that makes it easy to create and manage such rules.
They also sometimes offer professional services to help with the creation of these rules.
The best thing about Manual Rules is that they can be understood by a person. They are explainable, and therefore can be tweaked and adjusted when needed.
But the bottom line is that creating these rules takes a lot of effort.
You also need to ensure that they are accurate and maintain them over time.
To get you started, some companies come with pre-packaged rules, already organized into a taxonomy. For example, they would have a category "Price", with hundreds of words and phrases already pre-set, and underneath they might have sub-categories such as "Cheap" and "Expensive."
They may also have specific categories setup for certain industries, e.g. banks. And if you are a bank, you just need to add your product names into this taxonomy, and you're good to go.
The benefit of this approach is that once set up, you can run millions of feedback pieces and get a good overview of the core categories mentioned in the text.
But, there are plenty of disadvantages for this approach, and in fact any manual rules and word spotting technique:
1. Multiple word meanings make it hard to create rules
The most common reason why rules fail stems from polysemy (when the same word can have different meanings):
Staff Friendliness Table
Friendly OR friendliness
Staff friendliness
I was impressed by how friendly the person on the other end of the line was
Staff friendliness
✓
The lady who helped me was friendly
Staff friendliness
✓
Friendliness of staff
Staff friendliness
✓
Your website is very user friendly
Staff friendliness
✕
The young man on the phone was very friendly
Other
✕
2. Mentioned word doesn't equal core topic
Just because a word or a phrase is mentioned in text, it doesn't always mean that the text is about that topic.
For example, when a customer is explaining the situation that leads to an issue: "My credit card got declined and the cashier was super helpful, waiting patiently while I searched for cash in my bag."
This comment is not about credit cards or cash. It's about the behavior of the staff.
3. Rules cannot capture sentiment
Knowing the general category alone isn't enough. How do people think about "Price"? Are they happy or not?
Capturing sentiment with manually pre-set rules is impossible. People often do not realize how diverse and varied our language is. This is where text analytics and sentiment analysis come into play.
Sentiment Analysis Table
Guessed sentiment based on "great"
Actual sentiment
My coffee was great
Positive
Positive
My coffee was awful
Negative
Negative
My coffee was not great
Positive
Negative
My coffee was not that great
Positive
Neutral?
I did not think my coffee was great
Positive
Negative
I did not expect my coffee to be this great
Positive
Positive
I was disappointed with the quality of the coffee
Negative
Negative
I wasn't disappointed with the quality of the coffee
Negative
Positive
So, a sub-category like "expensive" is actually extremely difficult to model. A person could say something like "I did not think this product was expensive."
To categorize this comment into a category like "good price", you would need a complex algorithm to detect negation and its scope. A simple regular expression won't cut it.
4. Taxonomies don't exist for software products and many other businesses
The pre-set taxonomies with rules won't exist for non-standard products or services.
This is particularly problematic for the software industry, where each product is unique and the customer feedback talks about very specific issues.
5. Not everyone can maintain rules
In any industry, even if you have a working rule-based taxonomy, someone with good linguistic knowledge would need to constantly maintain the rules to make sure all of the feedback is categorized accurately.
This person would need to constantly scan for new expressions that people create so easily on the fly, and for any emerging themes that weren't considered previously.
It's a never-ending process which is highly expensive.
And yet, despite these disadvantages, this approach is the most widely used commercial application of Text Analytics, with its roots in the 90s, and no clear path for fixing these issues.
So, are Manual Rules good enough?
My answer to this is No. Most people who use Manual Rules are dissatisfied with the time required to set up a solution, with the costs to maintain it, and how actionable are the insights.
Text analytics approach 3: text categorization
Text categorization uses machine learning to classify text but requires extensive training data and struggles with emerging themes.
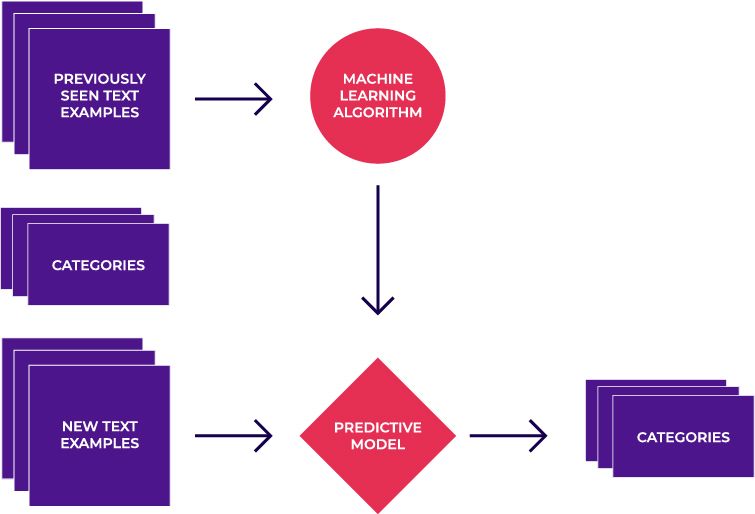
This approach is powered by machine learning (algorithms that learn from examples). The basic idea is that a machine learning algorithm analyzes previously manually categorized examples (the training data) and figures out the rules for categorizing new examples.
It's a supervised approach, meaning it learns from labeled data you provide.
The beauty of text categorization is that you simply need to provide examples. No manual creation of patterns or rules needed, unlike in the two previous approaches.
Another advantage of text categorization is that, theoretically, it should be able to capture the relative importance of a word occurrence in text.
Let's revisit the example from earlier sections. A customer may be explaining the situation that leads to an issue: "My credit card got declined and the cashier was super helpful, waiting patiently while I searched for cash in my bag."
This comment is not about credit cards or cash. It's about the behaviour of the staff.
The theme "credit card" mentioned in the comment isn't important, but "helpfulness" and "patience" is. A text categorization approach can capture it with the right training.
It all comes down to seeing similar examples in the training data.
Near perfect accuracy, but only with the right training data
There are academic research papers that show that text categorization can achieve near perfect accuracy.
Deep Learning algorithms are even more powerful than the old naïve ones (one older algorithm is actually called Naïve Bayes).
And yet, all researchers agree that the algorithm isn't as important as the training data.
The quality and the amount of the training data is the deciding factor in how successful this approach is for dealing with feedback. So, how much is enough? Well, it depends on the number of categories and the algorithm used to create a categorization model.
The more categories you have and the more closely related they are, the more training data is needed to help the algorithm to differentiate between them.
Some of the newer Text Analytics startups that rely on text categorization provide tools that make it easy for people to train the algorithms, so that they get better over time.
But do you have time to wait for the algorithm to get better, or do you need to act on customer feedback today?
Four issues with text categorization
Apart from needing to train the algorithm, here are four other problems with using text categorization for analyzing people's feedback:
1. You won't notice emerging themes
You will only learn insights about categories that you trained for and will miss the unknown unknowns.
This is the same disadvantage as manual rules and word spotting has: The need to continuously monitor the incoming feedback for emerging themes, and miscategorized items.
2. Lack of transparency
While the algorithm gets better over time, it is impossible to understand why it works the way it works and therefore easily tweak the results.
Qualitative researchers have told me that the lack of transparency is the main reason why text categorization did not take off in their world. For example, if there is suddenly poor accuracy on differentiating between two themes "wait time to install fiber" and "wait time on the phone to set up fiber", how much training data does one need to add, until the algorithm stops making these mistakes?
3. Preparing and managing training data is hard
The lack of training data is a real issue.
It's hard to start from scratch and most companies don't have enough or accurate enough data to train the algorithms. In fact, companies always overestimate how much training data they have, which makes implementation fall below expectations.
And finally, if you need to refine one specific category, you will need to re-label all of the data from scratch.
4. Re-training for each new dataset
Transferability can be really problematic!
Imagine you have a working text categorization solution for one of your departments, e.g. support, and now want to analyse feedback that comes through customer surveys, like NPS or CSAT. Again, you would need to re-train the algorithm.
I just got off the phone with a subject matter expert on survey analysis, who told me this story: A team of data scientists spent many months and created a solution that she ultimately had to dismiss due to lack of accuracy.
The company did not have time to wait for the algorithm to get better over time.
Text analytics approach 4: topic modelling
Topic modelling automatically detects word clusters but produces unclear results that are difficult to interpret and no longer recommended for modern feedback analysis.
Topic modelling is an older Machine Learning approach for text analytics that has largely been replaced by more advanced AI-driven methods. It is an unsupervised learning technique, meaning it analyzes raw text without predefined categories.
While it was once widely used, its limitations have made it less suitable for modern feedback analysis. However, we retain this section for reference and SEO benefits.
Topic modelling automatically detects recurring themes in text by grouping words that frequently appear together. The most common algorithm for this is Latent Dirichlet Allocation (LDA), which identifies word clusters (topics) within a dataset.
However, these topics are often difficult to interpret and lack transparency.
Example
A dataset of beer reviews might yield a topic with words like coffee, dark, chocolate, black, espresso.
Each review is assigned a mix of topics based on its content.
The weight of each topic within a review determines its relevance.
Why topic modelling is no longer recommended for feedback analysis
While topic modelling once offered an innovative way to process text data, it has major drawbacks:
Difficult to interpret: Topics generated by LDA are often unclear and require manual labeling.
Lacks transparency: Unlike modern AI models, topic modelling does not explain how or why words are grouped.
Limited business value: Outputs are not easily actionable for decision-making.
Inconsistent tracking: Changes in language use can make it difficult to monitor trends over time.
Due to these challenges, modern AI methods such as Thematic Analysis and LLM-driven approaches have largely replaced topic modelling for practical applications.
AI-Powered Text Analytics Software
See How Thematic Extracts Themes Transparently With No Training Data Required
Large Language Models understand context and meaning beyond keywords but face challenges with cost, hallucinations, and transparency that require human oversight.
While traditional text analytics models have their strengths, they often require extensive manual setup, rule updates, and labeled training data. This is where Large Language Models (LLMs) offer a breakthrough.
By understanding context, they can pick up themes that are custom for each business or even dataset.
On a small scale, anyone can use ChatGPT as a Text Analytics engine, and here's how.
For example, here's how ChatGPT-3.5 was used to analyze a school feedback dataset with 100 parent comments:
But more common than not, you will need to solve for errors since, unfortunately, LLMs will create duplicates of the same themes.
To create a scalable process, look for expert solutions that take advantage of LLMs like Thematic.
Thematic originally discovered themes bottom-up, but by using LLMs, they could create a custom top-level taxonomy of themes specific to each business use case. The discovered themes are then connected into this top-level taxonomy, bridging the gap between how people talk and how businesses talk about the same issues.
But how do LLMs actually work, and what makes them different from earlier text analytics approaches?
What makes LLMs different from older methods?
Unlike older methods that rely on predefined taxonomies, keyword matching, or supervised machine learning, LLMs can:
Recognize intent and meaning beyond keywords: LLMs have truly mastered language understanding and are able to determine the context and, with that, what a customer is truly expressing.
Detect sentiment nuances more accurately: They can pick up on sarcasm, mixed sentiment, and subtle emotions that simpler models miss.
Process multilingual data seamlessly: Unlike traditional models that require separate training per language, LLMs can analyze text across multiple languages without the need for translation.
The challenges of using LLMs in text analytics
Despite their strengths, LLMs aren't a plug-and-play solution for every text analytics task.
Businesses relying on them exclusively often encounter key challenges:
High costs: It's cost-prohibitive to use LLMs on huge volumes of data, for example for analyzing every contact center customer conversation.
Lack of transparency (black box issue): LLMs make decisions based on billions of learned parameters, but they don't explain why they generate a certain response. This makes accuracy verification difficult.
Hallucinations and inconsistencies: LLMs can generate false or misleading outputs that sound correct but aren't factually accurate. It needs human oversight!
Latency and speed issues: While LLMs are powerful, they are not suitable for real-time processing of high volume feedback, making traditional methods more practical in some cases.
To maximize the benefits of LLMs, businesses must use them strategically: applying them where they add the most value while leveraging other AI approaches for efficiency and reliability.
At Thematic, we combine LLMs with human-in-the-loop functionality to verify outputs and avoid black-box limitations.
Download NLP Generative AI Text Analytics Handbook
Beyond NLP: How LLMs Transform Text Analytics
Is your Text Analytics solution still relying on B-Grade NLP? Discover how large language models are revolutionizing text analytics, offering deeper insights than traditional NLP approaches.
Understand key NLP limitations and LLM advantages
View real-world results of AI-driven text analytics
Learn how self-learning AI eliminates manual updates
As discussed in "Our Secret Sauce: Human in the Loop," Thematic ensures experts validate and fine-tune AI-generated insights.
Rather than applying LLMs to every task, Thematic uses them selectively for high-value insights, balancing:
LLMs for deep, complex analysis
Machine learning and rules-based AI for efficiency
Human oversight to ensure accuracy
But while LLMs automate many aspects of text analytics, they aren't perfect. To avoid their limitations like hallucinations, high costs, and lack of transparency, Thematic takes a Hybrid AI approach, combining LLM-driven insights with machine learning and human expertise.
How Watercare used LLMs to turn crisis into insight
When two major storms crippled Auckland's water infrastructure, Watercare's support center was overwhelmed with a surge in customer complaints.
The usual feedback analysis process couldn't handle the scale or complexity.
To gain real-time insights from customer feedback, Watercare turned to Thematic's AI-powered analysis, which included LLMs to detect patterns and emerging themes instantly.
Identifying urgent issues: LLMs surfaced critical themes, such as long wait times and communication gaps, allowing Watercare to prioritize urgent fixes.
Sentiment understanding: Instead of just counting complaints, Thematic's LLM-powered model detected underlying frustration patterns, helping Watercare improve service recovery efforts.
Empowering decision-making: The customer experience team gained real-time dashboards, ensuring insights were shared across the organization.
Watercare's ability to act quickly on AI-powered insights helped restore customer satisfaction faster than manual methods ever could.
Text analytics approach 6: thematic analysis
Thematic analysis extracts themes bottom-up without training data, combining AI automation with human validation for transparent, research-grade insights.
All of the former approaches mentioned have disadvantages. In the best case, you'll get OK results only after spending many months setting things up.
And you may miss out on the unknown unknowns.
The cost of acting late or missing out on crucial insights is huge! It can lead to losing customers and stagnant growth.
This is why, according to YCombinator (the startup accelerator that produced more billion dollar companies than any other), "whenever you aren't working on your product you should be speaking to your users."
After Thematic participated in their programme, we've been asked for advice three times via a survey, once via a personal email, and also in person. YCombinator also use Thematic to make sense of all the feedback they collect.
When it comes to customer feedback, three things matter
Analysis you can act on (accurate, specific, actionable)
Ability to see emerging themes fast, without the need of setting things up
Transparency in how results are created, to bring in domain expertise and common sense knowledge
In my research, I've learned that the only approach that can achieve all three requirements is Thematic Analysis, combined with an interface for easily editing the results.
Thematic analysis: how it works
Thematic Analysis approaches extract themes from text, rather than categorize text. In other words, it's a bottom-up analysis.
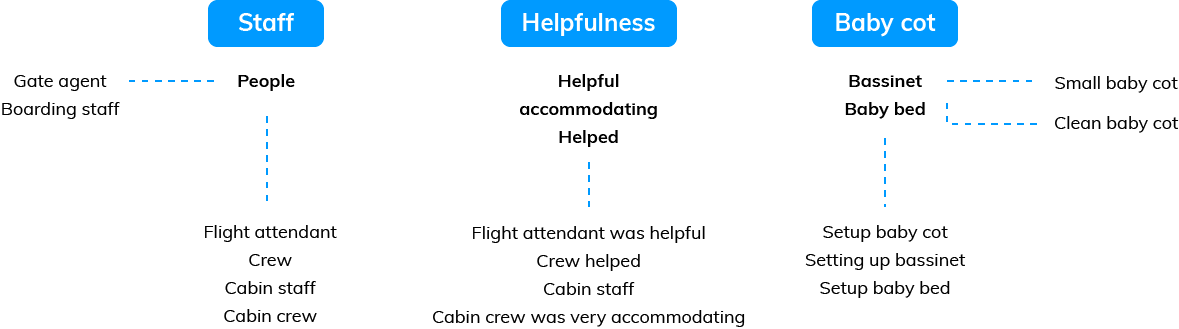
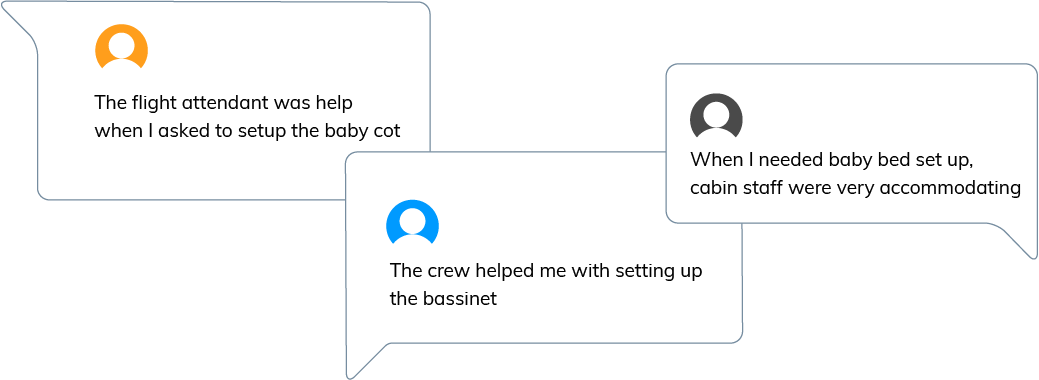
Given a piece of feedback such as "The flight attendant was helpful when I asked to set up a baby cot", they would extract themes such as "flight attendant", "flight attendant was helpful", "helpful", "asked to set up a baby cot", and "baby cot".
These are all meaningful phrases that can potentially be insightful when analyzing the entire dataset.
However, the most crucial step in a Thematic Analysis approach is merging phrases that are similar into themes and organizing them in a way that's easy for people to review and edit.
We achieve this by using our custom word embeddings implementation (a technique that represents words as numerical vectors to capture meaning), but there are different ways to achieve this.
For example, here is how three people talk about the same thing, and how we at Thematic group the results into themes and sub-themes:
Advantages and disadvantages of thematic analysis
The advantage of thematic analysis is that this approach is unsupervised, meaning that you don't need to set up these categories in advance, don't need to train the algorithm, and therefore can easily capture the unknown unknowns.
The disadvantages of this approach are that it's difficult to implement correctly.
A perfect approach must be able to merge and organize themes in a meaningful way, producing a set of themes that are not too generic and not too large. Ideally, the themes must capture at least 80% of verbatims (people's comments).
And the themes extraction must handle complex negation clauses, e.g. "I did not think this was a good coffee".
Who does thematic analysis?
Some of the established bigger players have implemented Thematic Analysis to enhance their Manual Rules approaches but tend to produce a laundry list of terms that are hard to review.
Traditional Text Analytics APIs designed by NLP experts also use this approach. However, they are rarely designed with customer feedback in mind and try to solve this problem in a generic way.
For example, when we tested Google and Microsoft's APIs we found that they aren't grouping themes out of the box.
As a result, only 20 to 40% of feedback is linked to top 10 themes: only when there are strong similarities in how people talk about specific things. The vast majority of feedback is uncategorized, meaning that you can't slice the data for deeper insights.
With our thematic analysis software, we have developed a Thematic Analysis approach that can easily analyze feedback from customers of pizza delivery services, music app creators, real estate brokers and many more.
We achieved this by focusing on a specific type of text: customer feedback, unlike NLP APIs that are designed to work on any type of text. We have implemented complex negation algorithms that separate positive from negative themes, to provide better insight.
Our secret sauce: human in the loop
Each dataset, and sometimes even each survey question, gets its own set of themes.
By using our Themes Editor, insights professionals can refine the themes to suit their business. For example, Thematic might find themes such as "fast delivery", "quick and easy", "an hour wait", "slow service", "delays in delivery" and group them under "speed of service".
One insight professional might re-group these into "slow" and "fast" under "speed of service". Another might organize them into "fast service" with "quick and easy", and "slow service" with "an hour wait" and "delays in delivery".
It's a subjective task.
Unlike black-box AI approaches, Thematic combines LLM-powered automation with human-in-the-loop validation. This ensures research-grade accuracy while maintaining transparency that compliance teams and executives can trust.
I believe more and more companies will discover Thematic Analysis, because unlike all other approaches, it's a transparent and deep analysis that does not require training data or time for crafting manual rules.
What are your thoughts?
Which approach is right for you?
We've created a cheat sheet which lists the text analytics approaches. Check it out below:
Thematic Text Analytics Cheat Sheet
Approach
Thematic Analysis
Manual Rules and Taxonomies
Large Language Models
Text Categorization
How it works
Themes extracted from text, similar ones merged
Manually crafted and maintained rules
Write a prompt to interpret the data
Categories trained on pre-categorized data
Who is it best for
Companies with small product portfolios or product-centric rating. Companies in non-standard industries.
Companies in well established industries that do not make major changes to their offering
Companies with expert reviewers or a one-off analysis for quick insights
Companies who have been consistently tagging feedback and do not make major changes to their offering
Data Volume Requirements
300+ feedback pieces/month
Any volume
Best for small dataset that fits a single prompt
300+ feedback pieces per category
Advantages
No data training required, captures emerging themes, easy to use, highly accurate, captures context
Easy to understand
No training required
Can be highly accurate and captures context
Disadvantages
Depends on reliability of AI models
Labor intensive, can't capture unknowns or sentiment
Making changes is labor intensive
Data model requires updating categories, not captures changes are labor intensive
Effort to setup
Days
Months
Days to Weeks
Months
Effort to maintain accuracy
Low: Anyone can maintain, just per need
High: Professional services (person) 1 day a week
Medium: Requires prompt engineering and management skills
Medium: Low if categories don't change, High if new categories need to be added
Transparency
Very Good
Good
Poor
Poor
Want to trial a demo of a modern LLM text analytics solution like Thematic for free?
See how Thematic delivers transparent, research-grade text analytics without training data or manual setup. Our platform combines LLM power with human-in-the-loop validation for insights executives can trust.
1. What are the main text analytics approaches for analyzing customer feedback?
Six main approaches exist: word spotting (keyword matching), manual rules (pattern-based), text categorization (machine learning classification), topic modeling (word clustering), large language models (context understanding), and thematic analysis (bottom-up theme extraction). Each has different accuracy, setup time, and maintenance requirements for enterprise feedback analysis.
2. What is the best text analytics method for enterprise feedback analysis?
Thematic analysis is best for enterprise feedback because it extracts themes without training data, captures emerging patterns automatically, and combines AI automation with human-in-the-loop validation. Unlike black-box methods, it provides transparent, auditable insights that research and insights teams can validate and executives can trust.
3. How does thematic analysis differ from text categorization?
Text categorization requires extensive training data and predefined categories, missing unknown patterns. Thematic analysis extracts themes bottom-up without training, automatically discovering emerging issues. Thematic combines LLM power with human validation through the Themes Editor, delivering transparent insights that categorization's black-box algorithms cannot provide.
4. What are the limitations of rule-based text analytics?
Rule-based methods require months of manual setup, can't capture sentiment or emerging themes, and need constant maintenance. They struggle with multiple word meanings and miss context (e.g., "credit card declined" in a comment about helpful staff). Accuracy often drops below 50% without extensive linguistic expertise.
5. Can AI analyze customer feedback without training data?
Yes. Thematic uses unsupervised thematic analysis with LLMs to extract themes automatically without training data or predefined categories. The AI identifies patterns, merges similar phrases, and organizes themes while researchers validate and refine results through human-in-the-loop oversight for research-grade accuracy.
6. What text analytics approach doesn't require manual setup or rules?
Thematic analysis requires no manual rules or training data. The AI automatically extracts and organizes themes from customer feedback in days, not months. LLMs identify patterns while the Themes Editor lets researchers validate and refine themes as needed, combining automation with transparent human oversight.
7. How do enterprises ensure text analytics results are transparent and auditable?
Use thematic analysis platforms like Thematic that combine AI with human-in-the-loop validation. Unlike black-box categorization or LLM-only approaches, Thematic's Themes Editor shows exactly how themes are identified and merged. Researchers validate AI-generated insights, creating auditable records that compliance teams and executives can verify.
8. Why are LLMs not sufficient alone for enterprise text analytics?
LLMs face challenges with cost, hallucinations (false outputs), and lack of transparency in decision-making. Without human validation, they produce inconsistent themes and duplicate categories. Thematic solves this by combining LLM power with human-in-the-loop validation, delivering transparent, research-grade insights executives can trust.
9. What's the difference between supervised and unsupervised text analytics?
Supervised methods (text categorization) require pre-labeled training data and predefined categories, missing unknown patterns. Unsupervised methods (thematic analysis, topic modeling) discover themes automatically from raw text. Thematic's unsupervised approach with human validation captures emerging issues while maintaining accuracy that supervised methods require months to achieve.
Share
Link Copied!
Request a demo of Thematic's Customer Intelligence Platform
Thematic turns fragmented feedback into one consistent source of customer truth — so every team acts on the same customer story. Up and running in days, not quarters.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.



.webp)