Word Spotting for Text Analytics: Quick & Dirty (But When Does It Fail?) (Part 1/5)
Is 'word spotting' a valid text analytics method? Learn its pros, cons, and when it's actually useful (hint: rarely for serious insights). Discover better alternatives.
For a long time, I’ve been planning to write a post to clarify what’s possible in the Text Analytics. Throughout my career, I’ve spoken with many people who are living through the pain of analyzing text and trying to find a solution.
Some try to reinvent the wheel by writing their own algorithms from scratch, others believe that Google and IBM APIs are the savior, others again are stuck with technologies from the late 90’s that vendors pitch as “advanced Text Analytics”.
So, I decided to post a series of articles that dig deeper into the 5 most common Text Analytics approaches and examines their pros and cons.
📌
Here's a quick link to the entire series.
👉Word Spotting for Text Analytics: Quick & Dirty (But When Does It Fail?)
Introducing word spotting: How to DIY in Excel or Python
Let’s start with word spotting. First off, it’s not a thing!
The academic Natural Language Processing community does not register such an approach, and rightly so. In fact, in the academic world, word spotting refers to handwriting recognition (spotting which word a person, a doctor perhaps, has written).
There is also keyword spotting, which focuses on speech processing.
But to my knowledge, *word spotting is not a used for any type of text analysis*.
But I’ve heard frequently enough about it in meetings to include in this review. It’s loved by DIY analysts and Excel wizards and is a popular approach among many customer insights professionals.
The main idea behind text word spotting is this: If a word appears in text, we can assume that this piece of text is “about” that particular word. For example, if words like “price” or “cost” are mentioned in a review, this means that this review is about “Price”.
The beauty of the word spotting approach is its simplicity.
You can implement word spotting in an Excel spreadsheet in less than 10 minutes.
Or, you could write a script in Python or R. Here’s how.
How to build a Text Analytics solution in 10 minutes
You can type in a formula, like this one, in Excel to categorize comments into “Billing”, “Pricing” and “Ease of use”:
And voilà!
Here it is applied to a Net Promoter Score survey where column B contains open-ended answers to questions “Why did you give us this score”:
It probably took me less than 10 minutes to create this, and the result is so encouraging! But wait…
Everyone loves simplicity. But in this case, simplicity sucks
Various issues can easily crop up with this approach.
Here, I’ve annotated them for you.
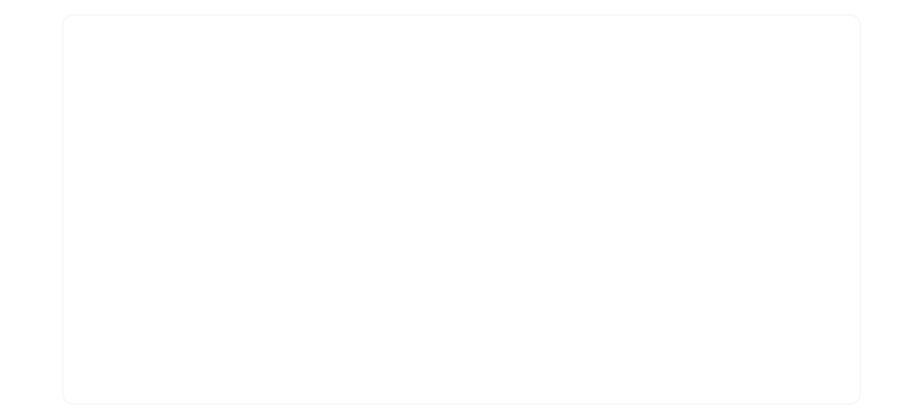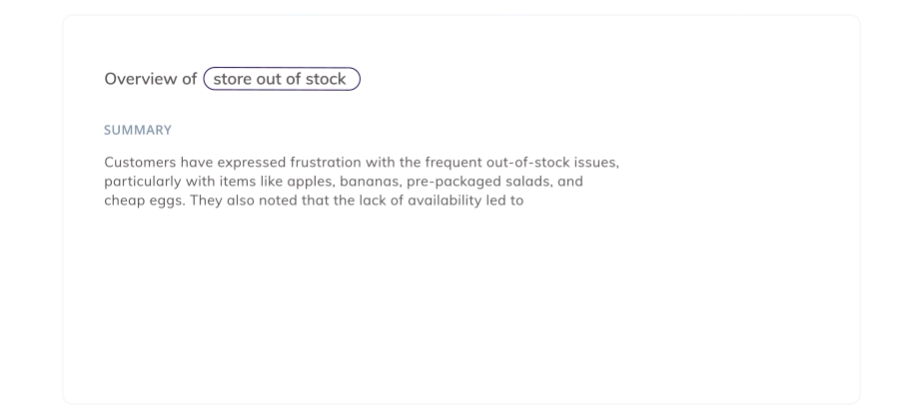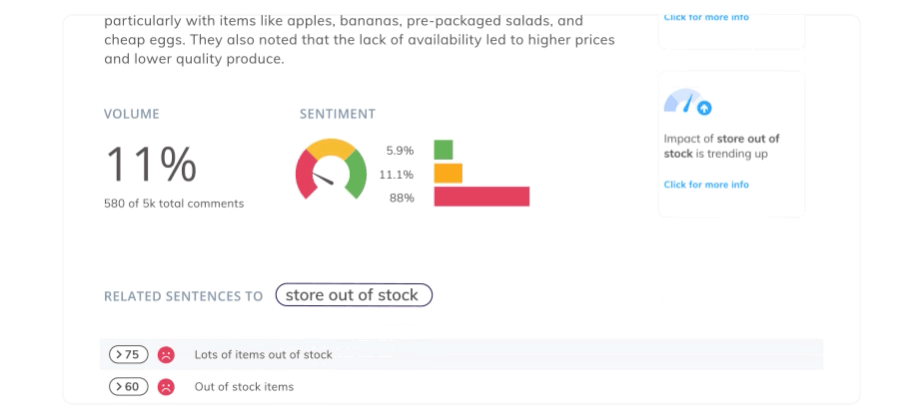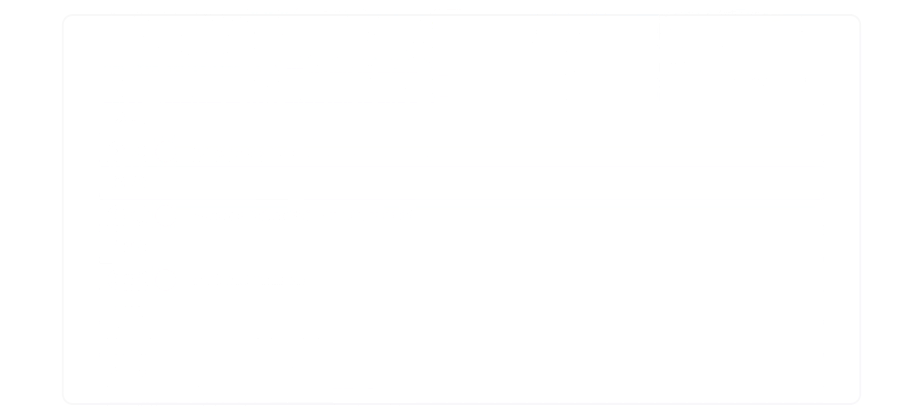
Out of 7 comments, here only 3 were categorized correctly. “Billing” is actually about “Price”, and three other comments missed additional themes. Would you bet your customer insights on something that’s at best 50 accurate?
Thematic
AI-powered software to transform qualitative data at scale through a thematic and content analysis.
You can imagine that the formula above can be tweaked further. And indeed, I’ve talked to companies who hand-crafted massive custom spreadsheets and are very happy with the results.
If you have a dataset with a couple of hundred responses that you only need to analyze once or twice, you can use this approach. If the dataset is small, you can review the results and ensure high accuracy very quickly.
When word spotting fails
As for the downside? Please don’t use word spotting:
If you have any substantial amount of data, more than several hundred responses
If you won’t have time to review and correct the accuracy of each piece of text
If you need to visualize the results (Excel will hear you swearing)
If you need to share the results with your colleagues
If you need to maintain the data consistently over time
There are also many other disadvantages to DIY word spotting, that we’ll discuss in the next post. I’ll also talk about what actually does work and is a good approach.
Text mining in excel can be time consuming, and if you have large amounts of data it can quickly become difficult to handle. Luckily, there are AI text analytics solutionsthat can find themes in your text automatically!
Thematic is one of these solutions, and you can get started with a free trial account.
Request a demo of Thematic's Customer Intelligence Platform
Thematic turns fragmented feedback into one consistent source of customer truth — so every team acts on the same customer story. Up and running in days, not quarters.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.