Know what great looks like: building trust in text analytics software
When you’re dealing with small amounts of feedback data, it’s fairly easy to keep track. There’s usually some amount of manual work involved, and you might find various analytics tools helpful.
As your company scales, the amount of feedback does too. Companies with positive revenue growth collect more customer experience data than non-growth companies.
Before you know it, your manageable feedback has become a monster!
You’re now dealing with large volumes of unstructured text data from multiple sources: reviews, social media, chat and support logs, surveys and community forums. More than manual tools and excel sheets can handle.
It’s a challenge. Many companies find it too hard or too time-consuming to use the large amounts of feedback data they’ve collected.
Enter Artificial Intelligence. Complex algorithms that promise to conquer big data utilizing text mining, machine learning and natural language processing. Text analytics software uses these techniques to analyze feedback at scale.
With text analytics software doing the heavy lifting, you can plug in your feedback sources - directly or using an api - and get instant access to data friendly dashboards and visualizations. With insights provided in near real-time, and workflows set up to detect changes in your data, your feedback analysis problems are solved. Right?
Unfortunately, with complexity comes questions. Can you trust your feedback data to an AI analytics solution when you don’t understand how it works? And how can you prove your results - and your actionable insights - are accurate?
Let’s take a look at how various AI text analytics solutions work, assess their trustworthiness, and examine how AI and people can collaborate to get the best insights from feedback faster.
Contents
- Why we need trust in text analytics software
- How AI algorithms make decisions
- Rule-based text analysis
- Text analysis: supervised categorization
- Text analysis: Topic modeling
- Text analysis: Deep Learning models
- How to build trust in AI-powered text analysis
- Thematic Analysis: breaking down feedback analysis into stages
- Enhancing AI-powered thematic analysis with human input
- Provide a pathway to great results
- Three other ways AI can enhance text analysis
Why we need trust in text analytics software
There are two main reasons why trust is key for text analysis software:
1. Analyzing customer feedback isn’t a new requirement. Market researchers have been analyzing customer sentiment at scale for decades. They know what great looks like. But it’s a painful and time-consuming task they’d like to go away.
2. Unlike other AI use cases, in feedback analysis, the output is used specifically for decision making. With important business decisions on the line, the research methodology must be solid. Sure, there might be occasional misses. People can also be biased when analyzing feedback. But overall, trust in accuracy is critical. Especially if you are reporting to people likely to question the research outcomes due to their own biases.
How AI algorithms make decisions
Customer feedback analysis is not the first application needing trust in AI. There’s AI-powered health diagnostics. And AI-powered risk assessment in the financial sector. Here, experts verify the final decisions, and this gradually builds trust in AI.
Because it’s important for experts to understand why AI makes certain decisions, researchers developed the idea of Transparent AI, also called Explainable AI. Experts are presented with the critical data points that led to a decision. For example, part of an X-ray scan and how it’s similar to other scans.
To understand how AI makes decisions and why transparency matters, let’s look an example where AI failed. Researchers built a model that recognizes whether an image is that of a husky or a wolf. Hundreds of examples were fed to AI for training, and some for testing.

AI said the above picture is a wolf, but it's a husky. Advanced analysis of the model revealed why. The AI made this mistake because it focused on the background, instead of capturing the facial features of the animals. Wolves had snow in the background, whereas huskies had greenery. As you can see, knowing how AI makes a decision is critical to understand if it can be trusted.
Rule-based text analysis
Automated text analysis has been around for a decade or so. The first approach was based on rules. For example, if words like “expensive”, “cheap”, “costs” etc. were detected in feedback, feedback was categorized under the topic “pricing”.
Initially, there's full trust in this approach. You create the rules, you know what they are and what they cover. But then things break down:
1. Complexity. Soon you realize that complicated Boolean rules are required to capture complexities of language. To match “friendly service”, you need a rule like “friendly” AND “cheerful” AND NOT “user friendly”. Over time, the set of rules becomes convoluted and cumbersome, possibly co-created by whole teams. Keeping track of them is difficult, and it becomes harder to retain trust.
2. Lack of discovery. To make sure rules pick up all emerging topics, you need to constantly monitor feedback. This is time consuming and often not done regularly. In situations where feedback changes often (e.g. with constantly evolving products or services), rules quickly become obsolete and trust erodes.
Despite these challenges, many text analysis tools still use this approach. This is because creating rules builds initial trust and a sense of control. By the time you realize trust can’t be maintained, many hours are already sunk into creating topics.
Text analytics using supervised categorization
A common AI-powered approach to text analysis is supervised categorization. Here, an AI model learns from examples of manually categorized pieces of text. A model trained on thousands of examples can be highly accurate.
The benefit of this approach is that you don’t need to think up rules. But just like with the husky vs. wolf example, we don’t really know how the AI captures a topic from the example. So, when the model makes a mistake, tweaking it becomes complicated.
In addition, this model can only pick up things it was trained on. So, just like the rules-based approach, it will miss any new emerging topics in the data. This also affects trust.
Text analytics using Topic modeling
Insights teams know the importance of discovery in feedback. Picking up on emerging issues early can be critical for a business. So, data scientists often suggest a topic modeling approach, also called Latent Dirichlet Allocation (LDA).
In topic modeling, an AI model is created from the text data alone. No rules or labeling required. Instead, the model captures how words are used alongside other words in raw text. It can then detect groups of words (topics) that capture specific aspects. For example, if you were to run it on beer reviews, you might find topics like (“toffee”, “burned sugar”, “malty”), (“coffee”, “chocolate”, “cacao”) and (“citrusy”, “fruity”, “grapefruit”). It’s quite a black box.
Topic modeling is often effective for a one-off data analysis of certain feedback. When a data science team used it on Facebook app reviews, they found an unexpected theme driving the negative reviews: it was that Candy Crush Saga crashed the app! Not the usual topics like “user experience”, “installation” or “news feed” that product managers wanted to include in their set of rules or supervised topics.
But when research teams try to use this approach for monthly reporting, things start to break down. Topic modeling can't maintain the same set of topics for consistency AND also discover new topics.
Text analytics using giant Deep Learning models
Recently, AI researchers turned to creating giant models like OpenAI’s GPT-3 and Google’s LaMBDA. Some of these have been applied to customer feedback.
These models are trained on huge datasets over several months. The energy requirements to train them are counted in millions of dollars. But once trained, the model can do a variety of impressive tasks: from solving math problems or conversing with you to creating poetry. A Google engineer working on LaMBDA was so convinced of the AI’s sentience that he helped it hire a lawyer to represent its interests!
Most AI researchers in and outside Google disagree that these giant models are sentient. That said, their fluency in language is impressive. You can load a set of data into GPT-3 and ask it to summarize what people are saying. GPT-3 will write a perfectly coherent summary, similar to those created by insights managers.
However, like other AI models, they often produce summaries that are off. If the 'creativity' parameter is not set correctly, the summary will include things that are not present in the data. Customers might say that the product is fun and engaging, but could have better design. But the AI model’s summary reports that customers want dark mode design, because that’s something it's often seen in the training data.
Another problem with such summaries is that they aren’t quantified. They don’t tell you how many people like or dislike something, or, for example, the overall impact of a given feature.
How to build trust in AI-powered text analysis
We’ve looked at a variety of approaches that automate feedback analysis: from transparent but hard to manage rules to huge AI black box models. Both have advantages and disadvantages.
Overall, there is a huge trend towards black box AI in the industry. Our language is simply too complex to be captured with transparent/explainable AI models. There is no way around using complex Deep Learning models, though not perhaps the largest ones.
So how do the best text analytics platforms convey trust?
1. Break down the analysis tasks into smaller pieces or stages. The smaller the stage, the more predictable and consistent results we can expect from AI.
2. Make it easy to enhance AI with human input. It’s easier for a user to provide input in stages. Ultimately, users should be able to tailor the analysis to make it more useful - but in a way that scales.
3. Provide a pathway to success. What does great look like? When it comes to text analysis, even people aren’t often sure if they 'picked up' everything. Use AI to compare feedback analysis results to those best-in-class. Provide suggestions on how to get there.
Let’s dig deeper into each of these.
1. Thematic Analysis: breaking down feedback analysis into stages
What do you do when you work with a giant AI model, and it doesn’t give you the results you need? You're stuck! So why not divide and conquer? It has been a winning strategy for many, from imperialist rulers to creators of sorting algorithms.
Formula 1 teams improve the performance of their cars by optimizing each part: the tires, the body, the engine and sometimes the driver!
Similarly, we can get more out of AI-powered text analysis by breaking it into stages. Here’s how:
When it comes to analyzing feedback, you'll have heard of many different approaches. But ultimately, most use themes - also called topics, categories or tags - to describe what people are saying. These themes are organized into a hierarchy (also called a taxonomy or code frame) to make it easy to work with them.
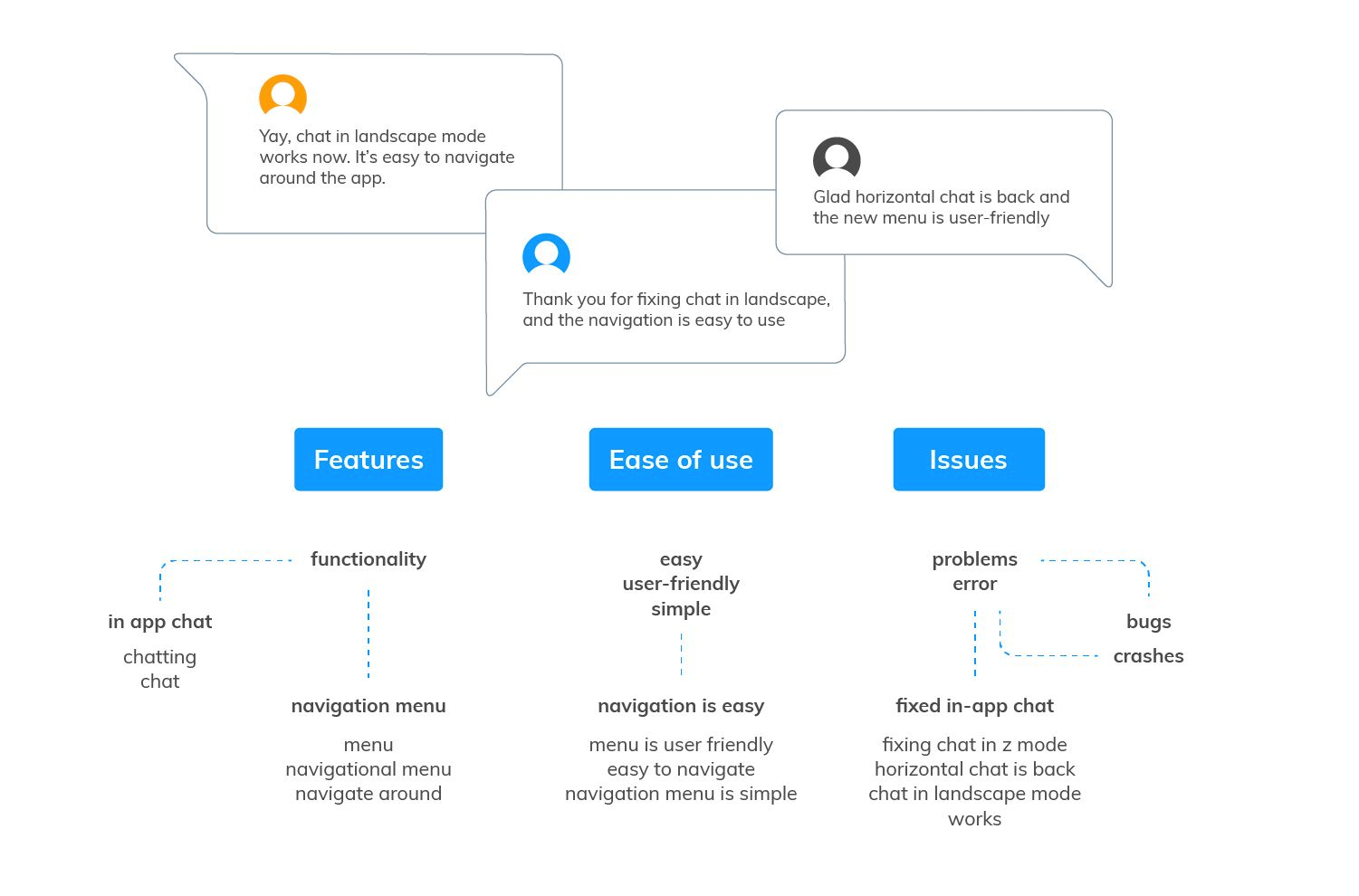
Some people start with a set of themes, others start from scratch and let themes emerge from the data. In qualitative research (where you work with a lot of text data), this is called thematic analysis.
When companies gather feedback at scale, there is usually historic data which informs the analysis process, and new feedback that is continuously added to historical data.
We can break down the analysis as follows:
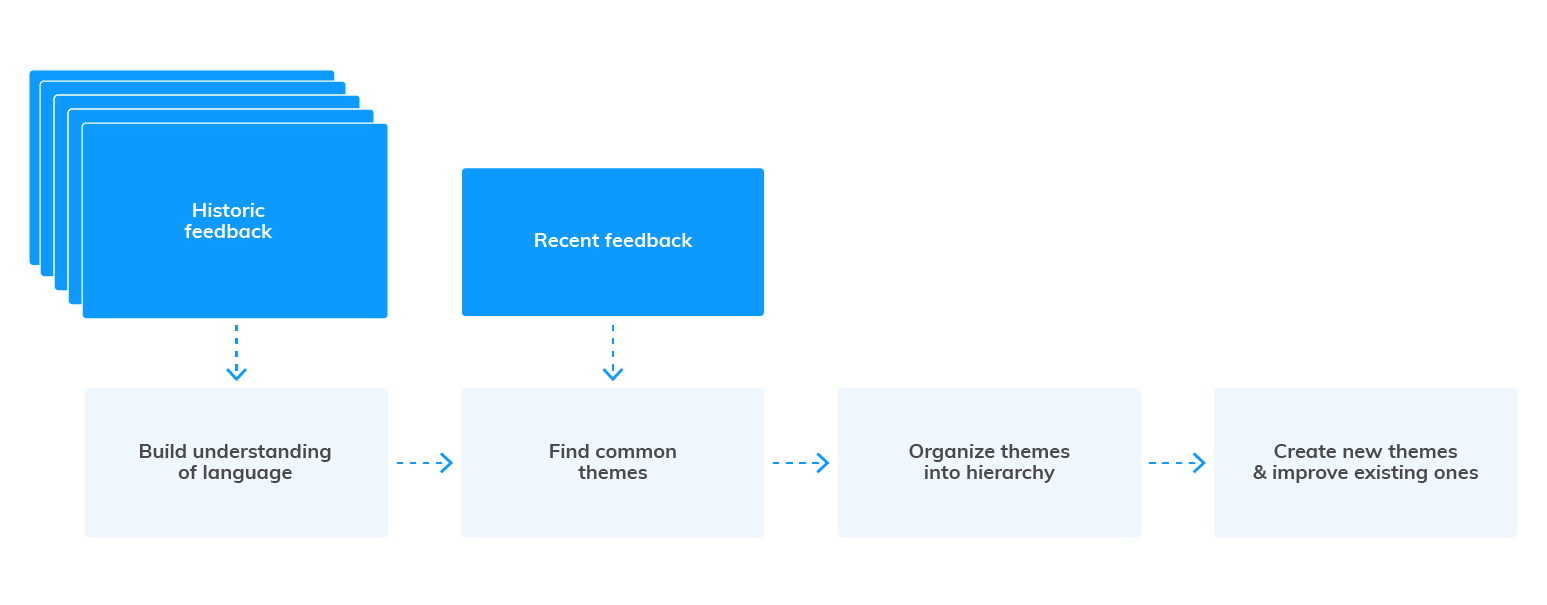
AI can help in all of these stages.
Most importantly, this makes the analysis semi-transparent and more trusted. Maybe you can’t see what’s happening inside each box individually, but you can tune them separately by providing feedback.
2. Enhancing AI-powered thematic analysis with human input
- Build an understanding of language in how people provide feedback and company-specific terminology. Some of this comes naturally to people, some to AI. For example, AI won’t know some of the product names, abbreviations etc, but it will know at least 10 ways people can misspell the word “knowledgeable”.
- Finding common themes is about finding patterns. AI shines when it needs to tirelessly sift through millions of pieces of feedback. What it doesn’t know is which theme is useful and which isn’t. For example, it might detect that people often mention “quick and easy” which isn’t that useful to know. Or that a time aspect is often mentioned alongside “contacting support”. People are better at deciding what’s useful and what’s not, especially if they have the context of what the user wants to do with the data. “Quick and easy” might be a good indicator that the key marketing message is working!
- Organizing themes is important for improving the quality of themes and the ease of working with them. For example, two themes might be discovered which mean the same thing. AI might merge some of them like “helpful support” and “accommodating support”. But a person can also teach it that “goes the extra mile” also falls into the same theme. We can't expect AI to know company-specific facts. For example, which products do we integrate with and which ones are our competitors? This is where AI and the user need to collaborate.
- Improving themes beyond what’s been discovered is also common. For example, AI might miss a theme because it’s not as common. But a user might still be interested in tracking it. For example, they might add “issues with login”. AI can suggest hundreds of ways a person might mention this and automatically verify whether it’s in the data.
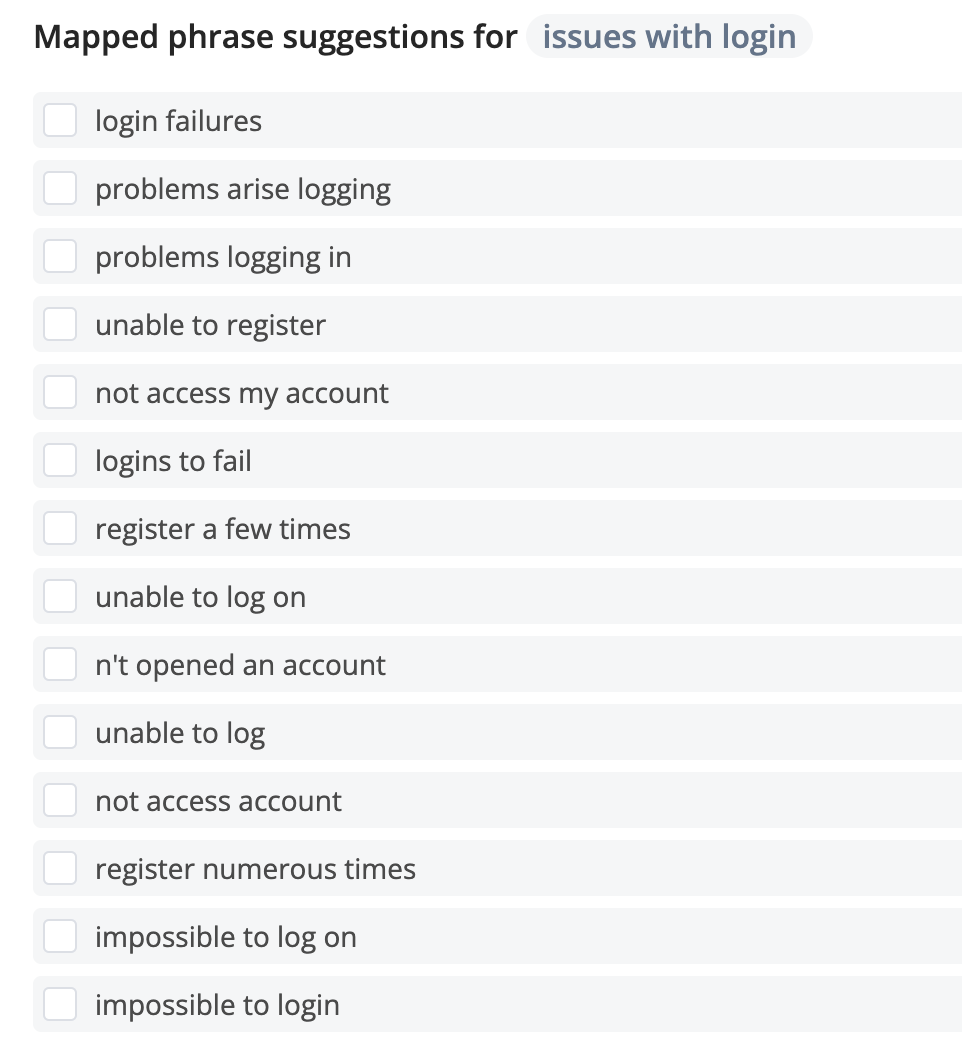
There’s usually a limit on how many themes are returned. Otherwise, it would be overwhelming. So another example of how AI and a person might work together is to dig deeper into a theme of interest or a subset of the data, which should be prioritized in discovery.
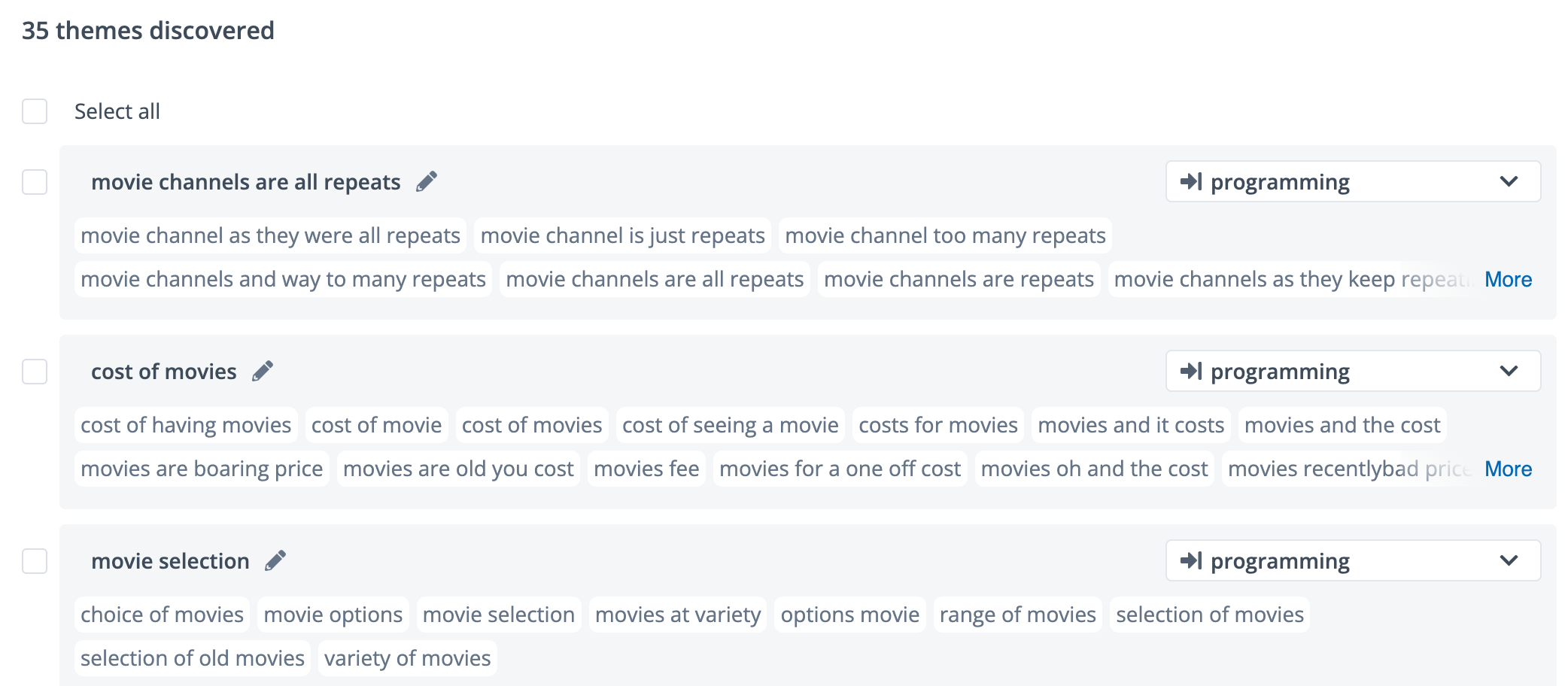
There are different ways of how this is implemented. At Thematic, we decided to focus on a self-service approach. We built a user interface that shows you the AI’s output in every stage and lets you iterate until you are happy with the overall outcome.
Keen to see how you can use Thematic on your own data? Book a consult with one of our team - we'd be thrilled to show you how Thematic works!
3. Provide a pathway to great results
If two people analyze the same 200 pieces of feedback, they will disagree. Both are likely to have doubts: Did I miss any critical themes? Did I portray everything correctly? Researchers are especially aware of the bias they bring into the analysis. Luckily, AI can help with this problem.
Again, we first break this down into parts.
What makes a set of themes both accurate and useful?
· Are they specific enough? If 50% of feedback is about installation issues, it’s accurate, but it’s not specific enough to act.
· Did we cover all there is to cover? This is where a lot of solutions with pre-defined taxonomies of themes struggle. They are accurate and specific on some of the data, but completely miss the rest. If what your company does is unique (e.g. not a standard hotel or airline), these taxonomies might miss the bulk of the feedback!
Believe it or not, but librarians back in the day had to be both specific and exhaustive when writing the catalogue cards for each book.
So where does AI come in? It can be trained to predict how many themes a piece of text should have vs. how many themes were discovered. It can calculate the specificity of a theme.
💡 Specificity is not all about the number of words. Something like “authentication” is more specific than “great product”. It’s about the amount of information (entropy) that theme carries in that context.
Coverage is now about how many sentences are tagged with themes. In fact, shorter feedback tends to have a larger percentage of themes, because it’s more succinct.
Knowing your specificity and coverage metrics is not enough. Ideally, you want to know how you compare to those best-in-class AND how to improve the results.
Three other ways AI can enhance text analysis
When it comes to text analysis, there are 3 other ways specific AI models can help.
1. Sentiment analysis
Some themes carry specific sentiment, e.g. “easy to navigate” or “authentication issues”. But majority of themes will have people who are happy or disappointed with that aspect of product or service. For example, a product might have features such as “reporting”, “integration with slack”, “onboarding flow”, and so on. Overall, you want to know: what are we doing well, and which features do we need to improve? Sentiment models can be applied to every part of the sentence linked to a theme to help with this.
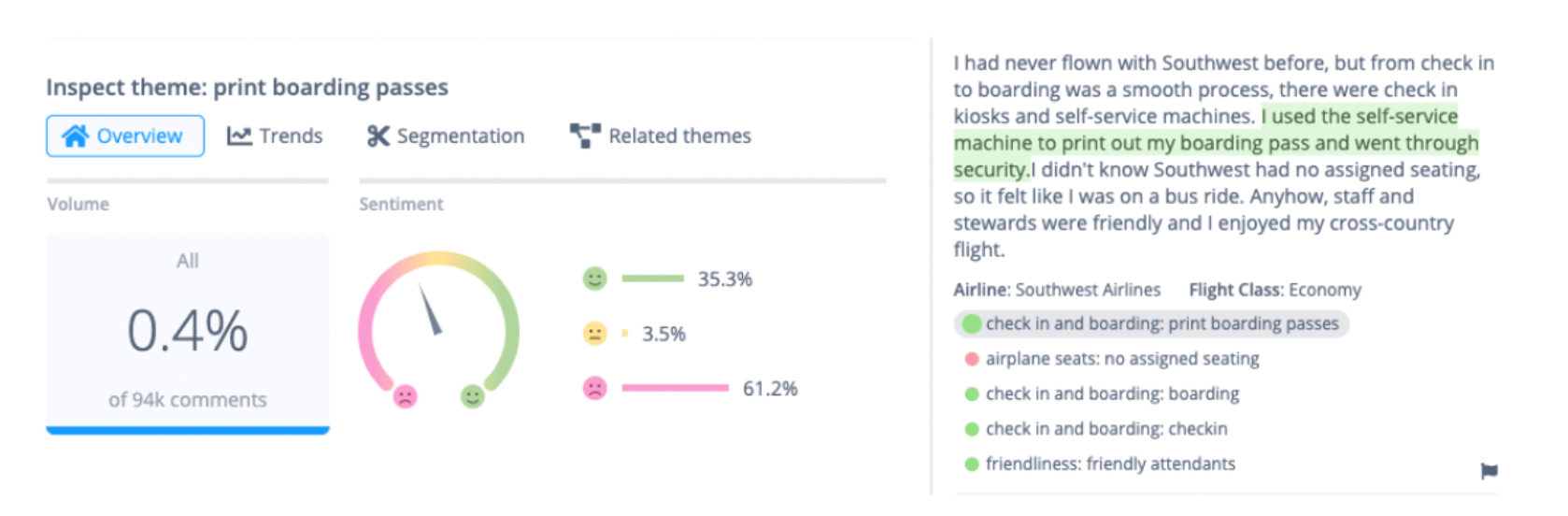
2. Feedback type
Themes have different importance depending on how they are mentioned in feedback. For example, a person might say “I’m a user on the premium plan. I have an issue with updating my credit card details.” The fact that they are on a premium plan is supplementary information. We can gather it from customer records. We’re more interested in what issues they currently have. This is especially common in support conversations.
AI-models can help detect what type of feedback it is. Is this about an issue, is it a question, a suggestion / request or 'other', i.e. supplementary information.
3. Summary of a theme
Let’s say we know that the theme is “credit card”, and we are looking at all feedback of type “issue”. There are might still be too much feedback to read to figure out best action. What kind of credit card issues are most common? This is where AI comes in again. It can cluster feedback based on similarity. It can then present these clusters, so that you can see which ones are most common and dive deeper into those of interest.
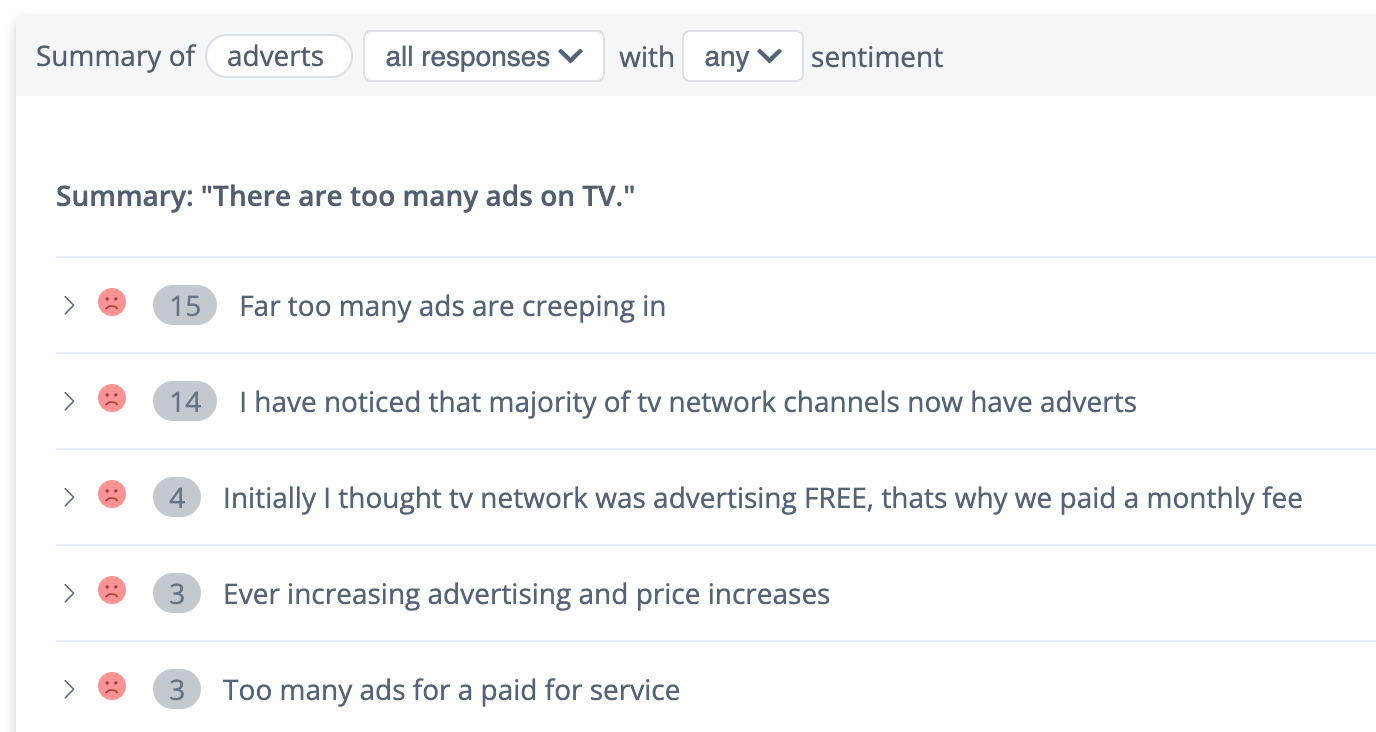
When it comes to analyzing feedback, AI is your best friend. But most importantly, you are AI’s best friend, if it’s designed in a way to learn from your feedback.
Ideally, you should be able to navigate feedback like a map: zoom out to see the lay of the land, and zoom in on the parts you are most interested in. It should give you the best route towards customer happiness. And it should help you get your team on board by providing a clever AI colleague who is an expert in insights!
Further reading
You can find out more about analyzing customer feedback in these guides:
- How to code qualitative data
- How to code and analyze open-ended questions
- Guide to thematic analysis software
- How to analyze customer and product reviews
- How to analyze survey data
We also have some free feedback tools and resources that may help you: