LLM providers constantly release "better" models. But better at what? Most benchmarks test coding and academic tasks, not summarization, instruction-following, or domain-specific work.
When you spend months optimizing prompts for a specific model, you're building technical debt. The moment that model gets deprecated (typically 12-18 months), you inherit a costly migration that often delivers worse results.
At Thematic, we've learned this lesson firsthand. Our customer feedback analytics platform depends on LLMs performing reliably across model generations.
Frontier LLM providers love announcing benchmark victories. A new model drops, the press release declares it "state-of-the-art," and the leaderboards shuffle. What gets less attention is the production systems that break when teams upgrade to these supposedly superior models.
As one of Thematic's ML engineers, I'll put it bluntly: I wouldn't say I'm an expert. More like a victim.
The challenge isn't whether newer models are "better" in some abstract sense. It's whether they're better for your specific tasks. The uncomfortable truth is that the answer is often no.
The benchmark problem
When you examine what LLM benchmarks actually measure, a pattern emerges.
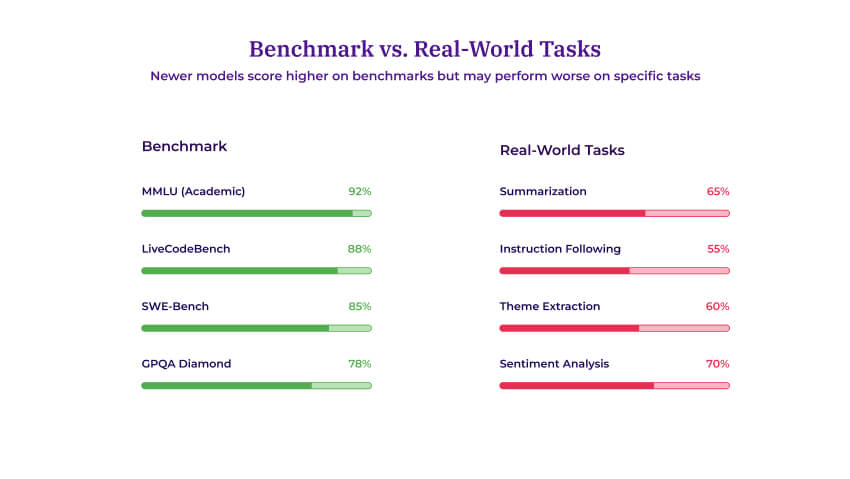
Take MMLU, the Massive Multitask Language Understanding benchmark. It covers 57 subjects ranging from abstract algebra to world religions, all multiple-choice. Models now score above 90% on MMLU. Impressive, until you realize this tells you nothing about whether the model can summarize customer feedback or follow complex multi-step instructions.
Benchmark
What It Tests
MMLU
Multiple-choice questions across 57 academic subjects
LiveCodeBench
Competitive programming from LeetCode, AtCoder, Codeforces
SWE-bench
Resolving real GitHub issues with code patches
GPQA Diamond
Graduate-level biology, physics, and chemistry questions
SimpleQA
Factual accuracy on short-answer questions
Comparing LLM benchmark scores versus real-world task performance, showing the gap between academic metrics and production results.
These benchmarks are heavily weighted toward coding and academic knowledge. A model that excels at competitive programming or graduate-level science may not perform as well on tasks like summarization or complex instruction-following.
For platforms like Thematic that analyze customer feedback at scale, these benchmark gaps matter.
Our customer feedback analysis pipelines require consistent theme extraction, sentiment detection, and summarization across thousands of open-ended responses. None of that shows up on standard leaderboards.
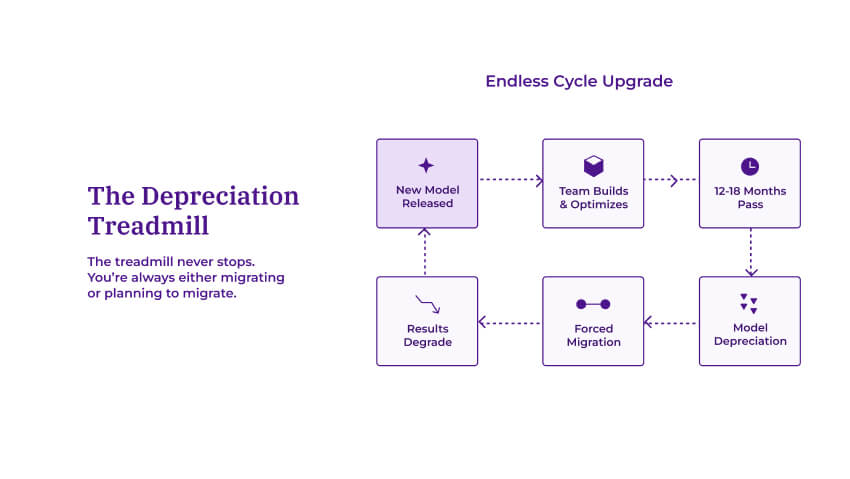
The deprecation treadmill
Flowchart illustrating the continuous cycle of AI model deprecation and migration that engineering teams face every 12-18 months.
For lightweight, open-source models, you control your own destiny. You can host them, maintain them, and keep them running indefinitely.
Frontier models are different. They're closed-source, hosted by providers like Amazon Bedrock, and those providers make business decisions that directly impact your production systems. The typical lifecycle: a model becomes available, teams build around it, and roughly 12-18 months later it could be deprecated—though this timeline varies by provider and model tier. In these cases, "upgrade" becomes mandatory, not optional.
The marketing says you're getting something better. The reality is often more complicated.
We recently tested a much newer "state-of-the-art" model on a project requiring complex multi-instruction following. The older model outperformed it significantly on this specific task.
Why? All models are trained on different data with different objectives. When models change, the way you prompt them needs to change too. Your carefully crafted prompts aren't just instructions. They're artifacts tuned to a specific model's quirks and capabilities.
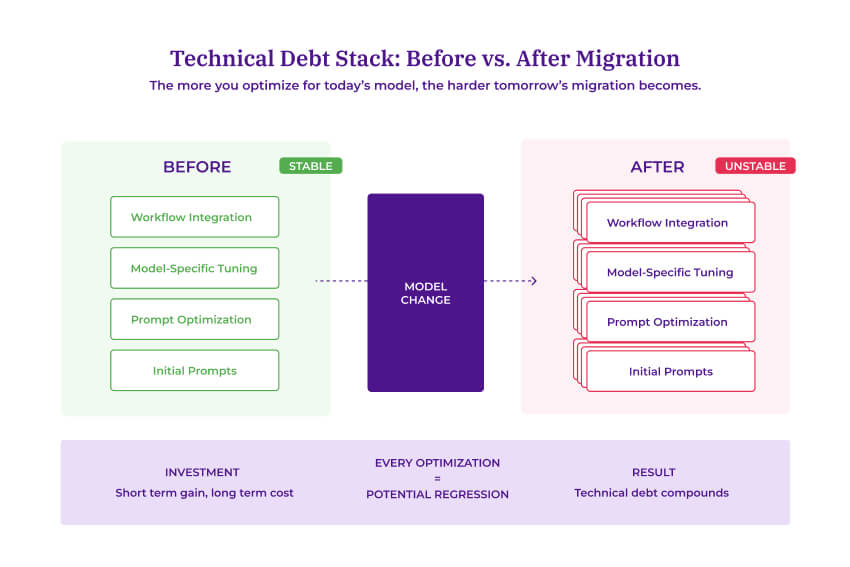
The Over-specialization problem
Diagram showing how LLM-specific optimizations create compounding technical debt when models are deprecated and teams must migrate.
Here's where it gets painful. The more time you invest optimizing prompts for a specific model, the higher the risk of degraded results when you're forced to "upgrade."
Prompt engineering isn't one-size-fits-all—it’s model-specificThe phrasing that coaxes excellent output from Claude may produce mediocre results from GPT-4. The instruction ordering that works on one Bedrock model may confuse its successor.
This creates a hidden form of technical debt:
Investment
Short-term benefit
Long-term cost
Prompt optimization
Better task performance
Migration headaches when model deprecated
Model-specific tuning
Excellent domain results
Total rebuild on model change
Workflow integration
Seamless production
Brittle dependencies
Every optimization that improves today's performance is a potential regression when tomorrow's model arrives.
The evaluation gap
You might assume sophisticated tooling exists to solve this. Automated systems that evaluate new models against your specific tasks and suggest prompt adaptations.
Tools like Langfuse promise this capability. In practice, they don't solve the core problem. You still have to do the actual work: defining metrics, building evaluation datasets, and determining what "good" looks like for your specific use case. We've largely ended up writing our own evaluation code, manually testing new models against production workloads before committing to migrations.
There's another wrinkle worth noting. When you use an LLM to judge LLM output (a common evaluation approach), models can be biased toward their own responses, though this effect varies by model and evaluation setup.
What this means for customer feedback analytics
If you're building products on LLMs, recognize that you're not just choosing a model. You're choosing a maintenance burden. Every model selection carries ongoing costs that compound over time.
This is particularly relevant for AI-powered customer feedback analysis, where consistency matters. When Thematic processes customer feedback, our users expect stable, reliable theme detection and sentiment analysis. A model migration that subtly changes how themes are categorized can undermine months of trend data.
The practical implications:
Benchmark skepticism is warranted. When a provider announces a new model that "achieves state-of-the-art results," ask: on what tasks? The answer is usually coding, math, and academic question-answering. Your customer feedback pipeline may see zero benefit, or active degradation.
Model diversity has value. Using multiple models across different task types reduces the blast radius when any single model gets deprecated. Not everything needs the frontier model.
Evaluation infrastructure is essential. Before any migration, you need rigorous testing against your specific workloads. Generic benchmarks are marketing materials, not migration guides.
Document your prompt reasoning. When prompts inevitably need rewriting, understanding why the original worked helps reconstruct the logic for new models.
The LLM landscape will keep churning. Models will keep getting deprecated. Newer won't always mean better, at least not for your specific needs. The teams that succeed will be the ones who treat model selection as an ongoing engineering discipline, not a one-time vendor decision.
Thematic is a customer feedback analytics platform that uses AI to analyze open-ended survey responses, reviews, and support conversations at scale. This article reflects our team's direct experience navigating model upgrades, deprecations, and the gap between benchmark promises and production reality.
Share
Link Copied!
Request a demo of Thematic's Customer Intelligence Platform
Thematic turns fragmented feedback into one consistent source of customer truth — so every team acts on the same customer story. Up and running in days, not quarters.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.