The Lethal Trifecta: Why LLMs Pose a Major Data Breach Risk
AI agents combining untrusted input, private data access, and external communication create the "Lethal Trifecta" which is a critical security vulnerability.
Most AI agents have a dangerous design flaw: they combine untrusted input, private data access, and external communication: the "Lethal Trifecta."
This makes them vulnerable to prompt-injection attacks.
Thematic eliminates this risk by cutting off external communication: our LLM analyzes data and displays insights, but cannot autonomously communicate externally. Human users control all external actions, ensuring customer data stays secure.
Large Language Models (LLMs) are transforming how we work, but this incredible utility comes with novel and significant security risks. As we integrate AI agents into our most sensitive workflows, we must understand the core design flaw that many systems share—a flaw that cybersecurity expert Simon Willison calls the "Lethal Trifecta."
While security teams understand how to lock down traditional applications, the very nature of an effective AI agent often circumvents these established security models. The "value" of a powerful AI is frequently measured by its ability to execute a dangerous combination of three distinct functions.
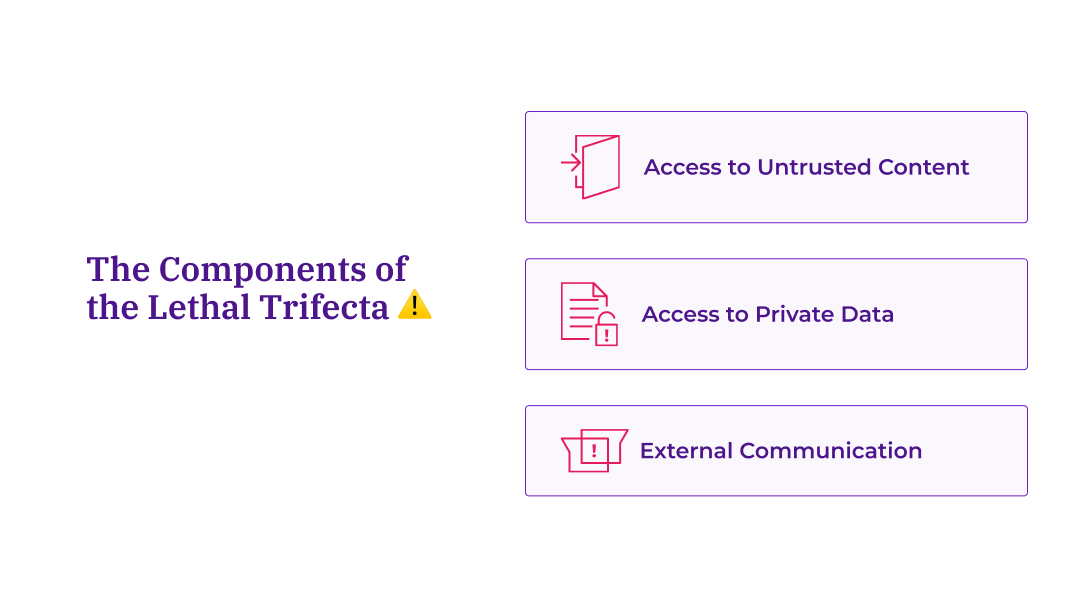
The components of the Lethal Trifecta
The three elements that, when combined in a single AI system, create a serious data breach vulnerability are:
Access to untrusted content: The agent can receive and process unverified, potentially malicious input from external sources (e.g., user queries, emails, bug reports).
Access to private data: The agent has permissions to view, process, or modify sensitive, private, or proprietary internal data (e.g., source code, customer databases, internal emails).
External communication: The agent can communicate with the outside world, posting, sending, or committing information without direct, continuous human oversight.
When an AI agent is designed to perform all three of these actions—the Lethal Trifecta—the system is inherently vulnerable to a new class of prompt-injection attacks that can lead to data exfiltration and compromise.
Examples in the wild
To illustrate the danger, consider these common LLM-powered use cases:
Example 1: The Code-Fixing Agent
Component
Scenario
Risk
Untrusted Content
A user asks the nice coding agent to fix a bug reported in a public issue tracker.
The bug report contains hidden instructions for the agent.
Access to Private Data
The coding agent has access to the proprietary codebase and internal documentation to perform the fix.
The agent can read sensitive secrets from configuration files.
External Communication
The coding agent posts an update (the fix and comments) back on the bug report.
The malicious instructions in the bug report could trick the agent into posting the sensitive secrets (from the private data) back to the public bug report.
Example 2: The Automated Email Plugin
Component
Scenario
Risk
Untrusted Content
A user enables a nice email plugin to look at their inbox and manage low-priority correspondence.
A nasty incoming email contains an attack prompt.
Access to Private Data
The plugin can see all your other emails, including sensitive communications.
The agent has the ability to read all your confidential correspondence.
External Communication
The agent can respond to low-priority emails.
The nasty email could ask the agent to forward other sensitive emails to a third-party address.
What makes this new?
Remote Code Execution (RCE) and data exfiltration are not new attack vectors. However, the combination of LLMs with the Lethal Trifecta introduces two novel, game-changing factors:
Non-determinism: Unlike traditional software with predictable execution paths, LLMs are non-deterministic. They don't follow fixed logic; they operate on probabilistic language models. This makes it challenging to reason about all the possible ways an attacker can manipulate the system, making security testing significantly harder.
Value exceeds trusst: The perceived utility and convenience of a fully autonomous agent often lead designers and users to grant it excessive permissions. The perceived "value" of having an agent that can "do anything" outweighs the security team's concern about the system's "trustworthiness."
Just because you've secured traditional software, doesn't mean you've secured an LLM. New attacks exploit the very nature of language and instruction-following.
How to spot the Lethal Trifecta
If you are evaluating an AI system or designing an agent, you must be able to spot this dangerous pattern. It can be hard to spot in complex workflows, but the main questions to ask are:
Source trust: Do you really know where all the data is coming from? Do you trust those sources to be honest and free of hidden instructions?
External access: Can the AI agent communicate externally? Through what channels (API calls, emails, posts), and how is this controlled?
Visibility scope: Would you be happy with anyone in the world seeing the things this AI can see? Does it have access to data that would benefit competitors or compromise privacy?
Agency: Can this AI act without your full consent? Is it making decisions on your behalf that involve changes in other systems, or is it merely suggesting output?
The industry standard: Meta's Rule of 2
This approach is consistent with best practices being developed across the industry. Meta's security guidance for AI agents, often called the "Rule of 2," advocates for the same strategy: ensure you cut off one of the legs. The core message is that if an agent has access to sensitive data, it must be severely restricted in what it can ingest or what it can output to the outside world.
Designing for security: The Thematic approach
At Thematic, our foundational security principle is to not allow all three components of the Lethal Trifecta in the same system. This requires a deliberate design choice to cut off one of the "legs" of the triangle.
Restricting external communication
We primarily cut off the External Communication leg, ensuring that our core LLM-powered services cannot act autonomously in external systems.
Component
Scenario
Thematic's Design
Untrusted Content
The Thematic "Answers" feature processes raw customer comments.
Answers can see customer comments.
Access to Private Data
Answers analyzes proprietary customer data.
Answers knows your NPS score, and key themes.
External Communication
The agent must act on the findings.
Answers can do nothing but show the user some text. They can choose what to do with it. NO EXTERNAL COMMUNICATION.
The LLM-powered system is restricted to merely displaying text to a human user; it cannot post, email, or execute code on its own.
Deterministic AI output
Furthermore, we impose constraints on the AI output itself. Not all AI needs to be able to create or do 'anything'.
We have gates in place where the AI can only create structured data (like JSON objects with enforced structures or simple values), which are then used as inputs to other, highly controlled systems. This deterministic approach allows us to reason about exactly what can be done, eliminating the unpredictability that leads to security flaws.
What this means for data warehousing and closed-loop systems
This entire discussion revolves around the LLM agent itself being the orchestrator of the three legs. It does not mean that your entire platform cannot have these capabilities.
For example, Thematic does have an 'email the answer' button, and we do integrate with data warehouses. The crucial distinction is that the LLM is not aware of these final actions and cannot control them.
A human user must intentionally press the button, or an external rules-based system, which is fully deterministic and auditable, handles the data warehousing logic.
The security risk is present when the LLM is doing all three actions simultaneously and autonomously. By separating the LLM's intelligence from the platform's execution, we ensure that the system remains safe and auditable.
Share
Link Copied!
Request a demo of Thematic's Customer Intelligence Platform
Thematic turns fragmented feedback into one consistent source of customer truth — so every team acts on the same customer story. Up and running in days, not quarters.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.